
Cpp Concurrency in Action读书笔记
目录
本文重点关注一下并发代码设计,无锁数据结构设计。内容主要来自于书籍《C++ Concurrency In Action》,以及一些网络课程,如CppCon、Mit OpenCourse。
术语
- interleaving:指来自不同线程的指令交错执行
- discipline:约束,比如lock-free discipline
- contention:争用
并发编程基础概念
- 为什么并发?
- 关注点分离:让一个线程/进程,专注于一件事情
- 性能:任务并行(执行任务的不同部分)、数据并行(计算数据的不同部分)
基于锁的数据结构
第六章中给出了若干线程安全的数据结构的设计,总体上看设计思路包括
- 设计优先,考虑需要进行支持的操作
- 确保线程持有锁的时间最短,
- 使用更细粒度的锁
- 引入虚拟节点。例如队列,可以用头尾虚拟节点将操作分离
- 使用锁和条件变量,提供wait和notify功能。考虑异常抛出时对其他请求锁的线程的唤醒。
下面摘抄几个例子
查询表
template<typename Key,typename Value,typename Hash=std::hash<Key> >
class threadsafe_lookup_table
{
private:
class bucket_type
{
private:
typedef std::pair<Key,Value> bucket_value;
typedef std::list<bucket_value> bucket_data;
typedef typename bucket_data::iterator bucket_iterator;
bucket_data data;
mutable boost::shared_mutex mutex; // 1
bucket_iterator find_entry_for(Key const& key) const // 2
{
return std::find_if(data.begin(),data.end(),
[&](bucket_value const& item)
{return item.first==key;});
}
public:
Value value_for(Key const& key,Value const& default_value) const
{
boost::shared_lock<boost::shared_mutex> lock(mutex); // 3
bucket_iterator const found_entry=find_entry_for(key);
return (found_entry==data.end())?
default_value:found_entry->second;
}
void add_or_update_mapping(Key const& key,Value const& value)
{
std::unique_lock<boost::shared_mutex> lock(mutex); // 4
bucket_iterator const found_entry=find_entry_for(key);
if(found_entry==data.end())
{
data.push_back(bucket_value(key,value));
}
else
{
found_entry->second=value;
}
}
void remove_mapping(Key const& key)
{
std::unique_lock<boost::shared_mutex> lock(mutex); // 5
bucket_iterator const found_entry=find_entry_for(key);
if(found_entry!=data.end())
{
data.erase(found_entry);
}
}
};
std::vector<std::unique_ptr<bucket_type> > buckets; // 6
Hash hasher;
bucket_type& get_bucket(Key const& key) const // 7
{
std::size_t const bucket_index=hasher(key)%buckets.size();
return *buckets[bucket_index];
}
public:
typedef Key key_type;
typedef Value mapped_type;
typedef Hash hash_type;
threadsafe_lookup_table(
unsigned num_buckets=19,Hash const& hasher_=Hash()):
buckets(num_buckets),hasher(hasher_)
{
for(unsigned i=0;i<num_buckets;++i)
{
buckets[i].reset(new bucket_type);
}
}
threadsafe_lookup_table(threadsafe_lookup_table const& other)=delete;
threadsafe_lookup_table& operator=(
threadsafe_lookup_table const& other)=delete;
Value value_for(Key const& key,
Value const& default_value=Value()) const
{
return get_bucket(key).value_for(key,default_value); // 8
}
void add_or_update_mapping(Key const& key,Value const& value)
{
get_bucket(key).add_or_update_mapping(key,value); // 9
}
void remove_mapping(Key const& key)
{
get_bucket(key).remove_mapping(key); // 10
}
};
链表
template<typename T>
class threadsafe_list
{
struct node // 1
{
std::mutex m;
std::shared_ptr<T> data;
std::unique_ptr<node> next;
node():next() // 2
{}
node(T const& value): // 3
data(std::make_shared<T>(value))
{}
};
node head;
public:
threadsafe_list()
{}
~threadsafe_list()
{
remove_if([](node const&){return true;});
}
threadsafe_list(threadsafe_list const& other)=delete;
threadsafe_list& operator=(threadsafe_list const& other)=delete;
void push_front(T const& value)
{
std::unique_ptr<node> new_node(new node(value)); // 4
std::lock_guard<std::mutex> lk(head.m);
new_node->next=std::move(head.next); // 5
head.next=std::move(new_node); // 6
}
template<typename Function>
void for_each(Function f) // 7
{
node* current=&head;
std::unique_lock<std::mutex> lk(head.m); // 8
while(node* const next=current->next.get()) // 9
{
std::unique_lock<std::mutex> next_lk(next->m); // 10
lk.unlock(); // 11
f(*next->data); // 12
current=next;
lk=std::move(next_lk); // 13
}
}
template<typename Predicate>
std::shared_ptr<T> find_first_if(Predicate p) // 14
{
node* current=&head;
std::unique_lock<std::mutex> lk(head.m);
while(node* const next=current->next.get())
{
std::unique_lock<std::mutex> next_lk(next->m);
lk.unlock();
if(p(*next->data)) // 15
{
return next->data; // 16
}
current=next;
lk=std::move(next_lk);
}
return std::shared_ptr<T>();
}
template<typename Predicate>
void remove_if(Predicate p) // 17
{
node* current=&head;
std::unique_lock<std::mutex> lk(head.m);
while(node* const next=current->next.get())
{
std::unique_lock<std::mutex> next_lk(next->m);
if(p(*next->data)) // 18
{
std::unique_ptr<node> old_next=std::move(current->next);
current->next=std::move(next->next);
next_lk.unlock();
} // 20
else
{
lk.unlock(); // 21
current=next;
lk=std::move(next_lk);
}
}
}
};
无锁数据结构速览
无锁数据结构设计和开发
本章节内容大幅来自于CppCon 2014: Herb Sutter “Lock-Free Programming。见参考文献中的相关链接。
基本概念
首先问一个问题,为什么要无锁?
- 减少算法、数据结构的阻塞、等待时间
- 避免锁和阻塞的问题:忘记锁、忘记释放锁、死锁、上错锁、粗粒度锁很方便但是性能很糟糕,锁之间的组合性不好
做无锁编程需要衡量的两点
- 我真的需要优化
- 我的优化确实有效
无锁编程的基础工具:事务思维、atomic<T>
- 所谓的事务思维,就是我们所熟悉的,ACID。原子性、一致性、隔离性、持久性。
- 在C++中是
atomic<T>,在C11中是atomic_*。这些原子变量提供的能力是- 对他们的读写都是原子性的,无锁的
- 根据设计需要,可以控制这些原子读写之间的重排情况
- 支持CAS指令。对于C++,提供
compare_exchange_strong、compare_exchange_weak和exchange。关于这三者的语义,可以参考C++ 多线程:原子类型(std::atomic)。弱版本允许(spuriously 地)返回 false(即原子对象所封装的值与参数 expected 的物理内容相同,但却仍然返回 false),即使在预期的实际情况与所包含的对象相比较时也是如此。对于某些循环算法来说,这可能是可接受的行为,并且可能会在某些平台上带来显著的性能提升。在这些虚假的失败中,函数返回false,而不修改预期。对于非循环算法来说,
compare_exchange_strong通常是首选。 - 允许原子化的类型是有限的,而且此时其内存布局可能发生变化。
如果模板参数类型很大,甚至会使用锁来完成
无锁的三种级别:
- wait-free:最强级别,no one ever waits。任何线程的操作都能在一个有界的操作时间内完成
- lock-free:稍弱级别,至少一个线程能在给定操作时间内完成
- obstruction-free:最弱的级别,在其他线程都暂停的情况下,才有一个线程能在给定操作时间内完成
这三个级别,在编写代码的时候,是可以起到一定的指导意义的。比如针对一个给定的数据规模,我们可以知道在使用K个线程上下时,算法是wait-free还是lock-free,还是obstruction-free。一般来说,当线程超过一定量级时,性能将会不可避免的从wait-free变为lock-free。
另外,要记得,我们最终的数据结构,不应该再要求外部的使用者,有任何同步操作。当然,使用者还是需要遵守构造、析构等生命周期的规范。换言之,超出生命周期的错误就不由数据结构负责了。
基本例子
-
DCL:double-checked lock。控制锁的粒度,我们可以用无锁方法先去读一下。在需要的时候再上锁。而且在这种情况下,我们还可以进一步优化原子变量的读取/写入次数。
// 以经典的,工厂方法中可能用到的延迟构造举例 // 当然更好的方法是用static局部变量 // 在类Widget中 atomic<Widget*> Widget::pInstance{nullptr}; Widget* Widget::getInstance() { // 可以尝试在进入时读取一次并保存 // Widget *p = pInstance; // 已经完成初始化后,这样能更快 if(pInstance == nullptr) { lock_guard<mutex> lock{mutex}; if(pInstance == nullptr) { pInstance = new Widget(); } } return pInstance; } -
生产者消费者场景: 考虑一个有若干槽位的,邮箱一样的数据结构。可以向其中任意的槽输入数据,并由消费者消费。注意下面的图片说明了在一个数据结构中,可能混合着wait-free部分,和obstruction-free部分。

 上面的设计并没有很完整(缺少了必备的CAS部分),但从上面的设计可以看出,无论无锁数据结构的场景多么复杂。其实最终关心的事情都是同样的,就是Compare And Set。
上面的设计并没有很完整(缺少了必备的CAS部分),但从上面的设计可以看出,无论无锁数据结构的场景多么复杂。其实最终关心的事情都是同样的,就是Compare And Set。 -
lock-free的单向链表:看起来简单,实际很复杂 先来看一下接口需求,这里只要5个:构造、析构、查找、push_front、pop_front。
下面是一个半成品。
template<typename T> class slist{ public: // 什么都不用做 slist() = default; // ~slist() { auto first = head.load(); while(first){ auto unlinked = first; first = first->next; delete unlinked; } } T* find(T t) const { // 这里就能看出无锁的优势,获取堆头只需要一个load,不用锁,之后的遍历也不需要锁住 auto p = head.load(); while (p && p->t != t) { p = p->next; } return p? &p->t : nullptr; } // push_front 会稍微复杂一点,因为可能有多个线程同时进入这里 void push_front(T t) { auto p = new Node; p->t = t; // 这里涉及到一次head的load,head存储的是之前的队头 p->next = head; // 交换,注意这里需要用weak,用strong也不会改变什么 // 我们需要的是循环直到成功,包括避免假失败 // 注意这里是另一个精妙设计,在compare_exchange_weak失败时,会令p->next=head; while (!head.compare_exchange_weak(p->next, p)) {} } // 但是,这里变得无法处理了 void pop_front() { // ... // 首先要保证,如果find还在使用,那么不能删除 // 其次要保证,如果和push_front交错运行。head能够正确表示。 // 很遗憾,这都不能优雅的简单做到 } private: struct Node{ T t; Node* next; } atomic<Node*> head{nullptr}; // 对于这种结构,一般都会禁止拷贝 slist(const slist&) = delete; slist& operator=(const slist&)=delete; }在pop_front中就会遇到ABA问题了。如果在pop的过程中,删除了一个节点,但是过一会儿因为push又被原地重建。此时head是无法区分出来,这是两个对象。解决ABA有很多种方案,针对本文可以延迟GC、添加辅助数据、不做真正删除等等。可能没有非常完美的,但是CppCon教程给出了一种常用办法。这需要对数据结构做重新设计。加入最重要的:
智能指针。// slist 的实现,实际上可以当作一个栈来使用了 template<typename T> class slist{ public: // 什么都不用做 slist() = default; // 有趣的是,因为这一次我们使用共享指针,析构什么都不用做了 ~slist() = default; // 这里使用reference提供更好的封装,可以控制对T的访问能力 // 而且如果有需要,也可以进一步控制复制能力,避免直接返回shared_ptr后,使用者多次复制增加引用计数 class reference { shared_ptr<Node> p; public: reference(shared_ptr<Node> p_): p{p_} {} // 可以根据自己的需要进行接口封装 T& operator*() { return p->t; } T* operator->() { return &p->t; } } auto find(T t) const { auto p = head.load(); // 这里看似简单,但是要知道的一个问题是,每一次的p = p->next; 都在修改共享指针的引用计数。 while (p && p->t != t) { p = p->next; } // 使用move,减少一次引用计数的变动。 return reference(move(p)); } // push_front 除了make_shared,并无大的改变 void push_front(T t) { auto p = make_shared<Node>(); p->t = t; p->next = head; while (!head.compare_exchange_weak(p->next, p)) {} } // void pop_front() { auto p = head.load(); while (p && !head.compare_exchange_waek(p, p->next)) {} // 在这里,共享指针显示出了强大的能力。此时的delete将会是自动的 // 如果有其他线程在持有共享引用,它也会被保留 } private: struct Node{ T t; // 引入共享指针,解决并发过程中的删除问题(延迟删除) shared_ptr<Node> next; } atomic<shared_ptr<Node>> head; // 对于这种结构,一般都会禁止拷贝 slist(const slist&) = delete; slist& operator=(const slist&)=delete; } -
再来看一个逐渐进行优化的例子 来看一个队列
template<typename T> class LowLockQueue { struct Node { Node (T val) : value(val), next(nullptr) {} T value; atomic<Node*> next; } public: LowLockQueue() { // 建立一个虚拟的节点,这个节点不作为有效数据 first = divider = last = new Node(T()); producerLock = consumerLock = false; } ~LowLockQueue() { while (first != nullptr) { Node* tmp = first; first = tmp->next; delete tmp; } } Node *first, *last; // 生产者消费者边界,只有这个需要原子化 atomic<Node*> divider; atomic<bool> consumerLock; atomic<bool> producerLock; bool Produce(const T& t) { Node* tmp = new Node(t); // 其实是利用原子变量上锁了 while (producerLock.exchange(true)) {} // 将虚拟节点last进一步向后移动 last = last->next = tmp; // 在插入时进行内存回收,惰性回收(莫名其妙的) while (first != divider) { Node* tmp = first; first = first->next; delete tmp; } // 离开临界区 producerLock = false; return true; } bool Consume( T& result) { // 一个非常经典的利用exchange做锁的写法 while(consumerLock.exchange(true)) {} // 由于虚拟节点的存在,因此当divider->next为空说明没有元素可以消费 if(divider->next != nullptr) { // consume时不做删除,只返回数据,并移动divider // 这里有拷贝,而且是在临界区内,堆争用 result = divider->next->value; divider = divider->next; consumerLock = false; return true; } consumerLock = false; return false; } }性能分析,通过建立不同数量的producer、consumer,来考察:吞吐量、伸缩性。结果见下面这张图。
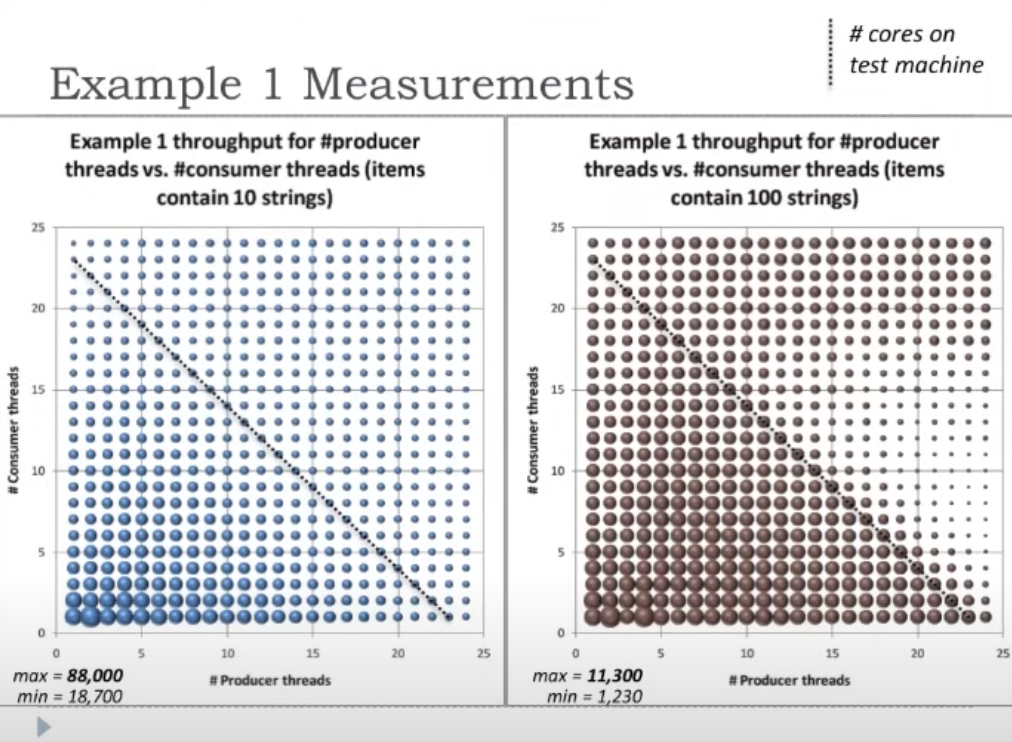
可见,在这种设计下,最终的性能和核数(24个)相关,当超过系统的物理核心数量之后,吞吐量不再上升,甚至下降。但是并没有很好的体现,线程数量上升时,吞吐量呈现类似的线性上升的趋势。也就是说scalability是有问题的。
当然上面有很大的优化空间,先让我们看一下。避免堆争用,不要再将对数据元素的拷贝这样的操作,放在临界区内。
// 以下只列出改动的部分 struct Node { Node(T *val): value(val), next(nullptr) {} T* value; atomic<Node*> next; } LowLockQueue() { first = divider = last = new Node(nullptr); producerLock = consumerLock = false; } bool Consumer(T& result) { while (consumerLock.exchange(true)) {} if (divider->next != nullptr) { T* value = divider->next->value; divider->next->value = nullptr; divider = divider->next; consumerLock = false; // 核心修改,现在拷贝在临界区外面了 result = *value; delete value; return true; } consumerLock = false; return false; } // producer也要做简单的修改,只需要创建一个指针。不过producer准备一个Node是在临界区之前的工作还可以进一步的减少消费者的争抢。这里有几点关于之前的优化思路值得思考。
- 为了让producer做延迟删除,牺牲了consumer操作时本身就具有的局部性
- 在之前的版本中,要么producer、要么consumer,要负责删除工作,这时这个线程不得不同时访问队列的两端,缓存性能会变差
LowLockQueue() { // 不再使用divider first = last = new Node(nullptr); producerLock = consumerLock = false; } bool Consume(T& result) { // consumer之间隔离 while(consumerLock.exchange(true)) {} if(first->next != nullptr){ // 每一次first都是一个虚拟节点,只有first->next才是可以消费的 Node* oldFirst = first; first = first->next; T* value = first->value; first->value = nullptr; consumerLock = false; // 在临界区之外进行拷贝 result = *value; delete value; // 删除更早的虚拟节点 delete oldFirst; return true; } consumerLock = false; return false; } bool Produce(const T& t) { // 临界区之前,准备新节点 Node* tmp = new Node(t); while (producerLock.exchange(true)) {} // 生产者临界区很简单,只需要修改last即可 last->next = tmp; last = tmp; producerLock = false; return true; }最后,还要考虑cache对齐。只要两个变量,可能被不同的线程使用,就应该考虑为其分配在不同的缓存行上
struct alignas(CACHE_LINE_SIZE) Node { // ... 内容不变 } alignas(CACHE_LINE_SIZE) Node* first; alignas(CACHE_LINE_SIZE) atomic<bool> consumerLock; alignas(CACHE_LINE_SIZE) Node* last; alignas(CACHE_LINE_SIZE) atomic<bool> producerLock; -
总结下来就是
- 更小的临界区
- 不同线程,尽量访问数据结构的不同部分,获取更好的缓存性能(比如上面的first、last)。尤其是first的边界测试也不用
first==last,而是first->next==nullptr - 缓存行的对齐设置,减少假共享
重点推荐参考
- 1.84.0版本boost,第20章Boost.Lockfree
- 论文:Simple, Fast, and Practical Non-Blocking and Blocking Concurrent Queue Algorithms
- CppCon 2014: Herb Sutter “Lock-Free Programming (or, Juggling Razor Blades), Part I”
- CppCon 2014: Herb Sutter “Lock-Free Programming (or, Juggling Razor Blades), Part II”
- 17. Synchronization Without Locks