
C/C++:内存对象模型
目录
本文记录对C/C++内存对象模型的学习,内容主要来自于《深度探索C++对象模型》。
本文在记录过程中,以Visual Studio 2022为测试环境,采用C++20标准
注意,C++标准对于内存模型,其实并没有绝对严格的定义,只是会有一些保证要求。不过实际上,各个厂商,VS、GCC、Clang,最终的实现都趋于相同。
术语
- ADT:抽象数据类型模型。用一组表达式提供“抽象”。可以理解为是C++中提供的各类operator。
- OOP:面向对象模型。是C++中提供的类机制
- PO:procedure oriented,面向过程。传统C风格,函数和数据分离。
由于C++支持多种编程范式,即所谓的programming paradigms,例如上面的ADT、OOP、PO。保持在同一个范式内是最稳定的。而如果要跨范式进行开发,就需要特别注意
成员分类和对象模型
基础情况
数据成员有两种
- 静态数据成员
- 非静态数据成员
成员函数有三种
- 静态函数
- 非静态
- 虚函数
当成员分类确定之后,就可以开始思考对象的内存模型。
先看一下两种未被采纳,但是仍值得参考的对象模型
- 简单对象模型:对象内存中,存储着到所有成员(包括数据和函数)的指针,有多少个成员就有多少个指针。
- 表格驱动对象模型:对象内存中,存储到数据成员表,到成员函数表的两个指针。其中数据成员表内按顺序排列存储着各个数据成员。成员函数表则是一系列到函数的指针。
C++真正使用的对象模型是从简单对象模型派生而来的。从成员角度来看
- 数据成员: 2. 对象外:静态成员 3. 对象内:非静态存储
- 成员函数: 5. 对象外:静态和非静态函数,虚函数表vtbl 6. 对象内:虚函数表指针vptr
而C++这种对数据和操作的封装,相比于C来说,不会带来过多的额外成本。一般来说
- 数据成员直接内含在每一个对象内存布局中
- 非inline成员函数只会产生一个函数实体,不会出现在对象内存布局中
- inline成员函数,则会在每一个调用者所在的位置,产生一个函数实体。
而额外的空间和时间成本来自于两种情况。
- 虚函数机制:每一个有多态的基类,会增加一个虚函数表指针。
- 虚函数表:表内有若干虚函数指针,同时,还会通过thunk的方式,保存到其他虚表的距离,因为如果是以非第一继承顺序的类型指针/引用进行多态调用,需要调整此时的指针。才能获取到完整的虚表。
- 虚继承:参考C++普通继承、多继承、虚继承内存空间排布分析、C++:类的内存布局
- 为了满足虚基类只有一个内存实例的要求,因此需要再建立若干个虚基类表,在不同的虚继承路径上,均需要增加一个vbptr指针来保存对应虚基表的地址。虚基类的subobject一般存放在最底层派生类成员的后面。如果是完全虚继承(即所有的基类都是virtual,则按顺序都在派生类成员后面排列,可见此时结构和常规的继承完全相反了)
虚基类指针vbptr指向虚基类表vbtable,虚基类表中存放的是,数据相对于虚基类指针的偏移,从而根据偏移找到数据 虚基类表是一个存储了,当前vbptr地址到自己和其他所有自己的虚基类的vfptr的偏移量的表格。派生类的虚基类表是最大的
- 因为虚基类被单独存储,所以继承路径上,如果有添加了新的虚函数,不从虚基类重写的,也不能存储在虚基类的虚函数表中,而是要存储在路径中的对应类型自己的虚函数表内。
- 在派生类和虚基类之间,可能插入0x00000000(有一些条件),一个四字节的填充物。在该填充物之前,派生类可能会再有一些padding。在visual studio下,可以通过
#pragma vtordisp(off)控制。
设计上,不建议在虚基表中,存储任何非静态成员。
- 为了满足虚基类只有一个内存实例的要求,因此需要再建立若干个虚基类表,在不同的虚继承路径上,均需要增加一个vbptr指针来保存对应虚基表的地址。虚基类的subobject一般存放在最底层派生类成员的后面。如果是完全虚继承(即所有的基类都是virtual,则按顺序都在派生类成员后面排列,可见此时结构和常规的继承完全相反了)
padding
为了对齐需求,所进行的数据填充。padding有两种可能性
- 在成员之间的填充
- 在对象的边界之间进行填充
尽管内存是以字节为单位,但是大部分处理器并不是按字节块来存取内存的.它一般会以双字节,四字节,8字节,16字节甚至32字节为单位来存取内存,称为内存存取粒度。如果不进行内存对齐,存取某一个数据,会出现跨内存存取粒度的情况。更甚者,在将这类数据存入寄存器时,甚至需要将来自多个存取粒度的数据,进行合并,才能存入。降低了运行效率。
内存对齐有清晰的规则,参考C/C++内存对齐详解。
简单来说,通常有如下规则。在对齐参数是x(字节)的前提下。
- 对于一个长度为y字节的数据成员,它将被对齐到$\min(x,y)$的整数倍的位置。
- 对于类型整体,将会使用成员中对齐要求最大的成员,假设为y,对齐到$\min(x,y)$的整数。(在末尾填充若干)
注意当存在多态时,由于虚函数表指针长度为4、或8,此时它可能是对齐要求最大的成员
比如在32位系统下,对齐参数为4,而可选值一般是1,2,4。64位系统上,则默认为8,一般会选1,2,4,8。对应的控制方法主要是#pragma pack (4),括号内代表了对齐参数。
#pragma pack(1) // 可以多尝试1,2,4,8。看看和自己理解的是不是一样的
struct Test {
int a;
char b;
short c;
char d;
};
struct Test2 {
double a;
char b;
};
考虑继承
在继承的情况下,基类的实体部分称为subobject。
这里还可以参考一下两种并未使用的对象模型
- 在简单对象模型上改造:在对象内存储一系列指向不同基类的suboject的指针
- 在表格驱动模型上改造:增加一个基类指针表格,并在对象内增加一个指向基类表格的指针。
以上两种方式,最大的问题是引入了过多的间接级数,而且这种级数随着继承深度加深而变深。当然也不是完全没有好处,使用指针的话,可以允许基类在某些修改情况之后,不需要对派生类进行重新编译。
- 单继承:内存布局按照先基类、再派生类进行排列
- 多继承:内存布局按照声明的继承顺序排列,最后是派生类的成员。派生类会将自己的所有虚函数,放到第一个基类的虚函数表中。
- 菱形多继承(非虚继承):和多继承一样,而且不同的路径上都会各自有一份基类的内存布局,如果有虚函数,其虚函数表也是不同的
- 虚继承:
- 部分虚继承:即仍有非虚基类,派生类还可以将自己的虚函数放到该非虚基类的虚函数表中
- 完全虚继承:全都是虚基类,此时派生类只要有一个新的虚函数,就必须为自己准备一个新的虚函数表。(注意虚析构函数不算新的虚函数)
- 菱形多继承(虚继承):综合上面的3、4
如下代码
struct Test {
int a;
int b;
virtual void func() {
cout << "in Test" << endl;
}
virtual ~Test() {
cout << "Test ?" << endl;
}
};
struct TestA : virtual public Test {
int Aa;
//virtual void func()override {
// cout << "in TestA" << endl;
//}
virtual void func2() {
cout << "in TestA func2" << endl;
}
virtual ~TestA() {}
};
struct TestB : virtual public Test {
int Ba;
virtual void func()override {
cout << "in TestB" << endl;
}
virtual ~TestB() {}
};
struct Test3 : virtual public TestA, virtual public TestB {
int cc;
virtual void func() {
cout << "in Test3" << endl;
}
virtual ~Test3() {}
};
最终形成的内存布局如下
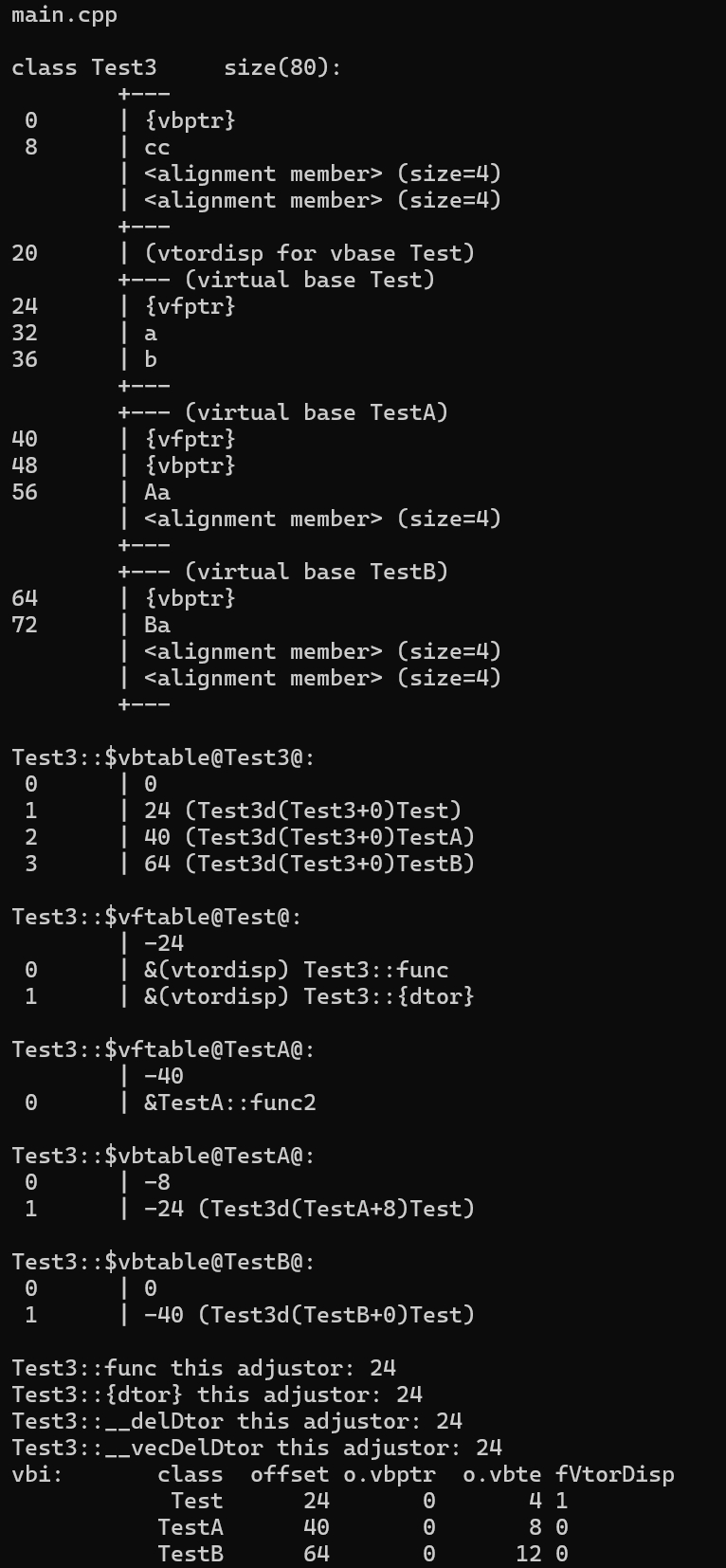
虚析构函数和普通虚函数一样,是会被覆盖的。派生类的析构函数会覆盖到基类的虚析构函数原本所在虚表中的位置。析构函数调用顺序和构造相反,由编译器按顺序执行。(尚不清楚原理,如何保证调用链)
兼容C的布局
推荐思路
- 使用组合而非继承,即在C++内使用C类型的对象
兼容带来的问题
- 在C中允许单一元素数组放在struct尾端,并借此让该类型对象拥有大小可变的数组
struct mumble { /* stuff */ char pc[1]; }; // 分配空间,并拷贝字符串 struct mumble *pmumbl = (struct mumble*) malloc(sizeof(struct mumble) + strlen(string) + 1); strcpy(&memple.pc, string);但是这个技巧在C++中不一定有效。因为不同的访问权限的数据成员(即不同的access sections),排列并没有严格限制(待确认)。
为什么是指针或引用
这一点可能令人困惑,为什么C++中使用多态,必须要以指针,或者引用的形式。
而这从内存布局上就能很好的理解。考虑下面这个混合了堆栈空间分配的情况
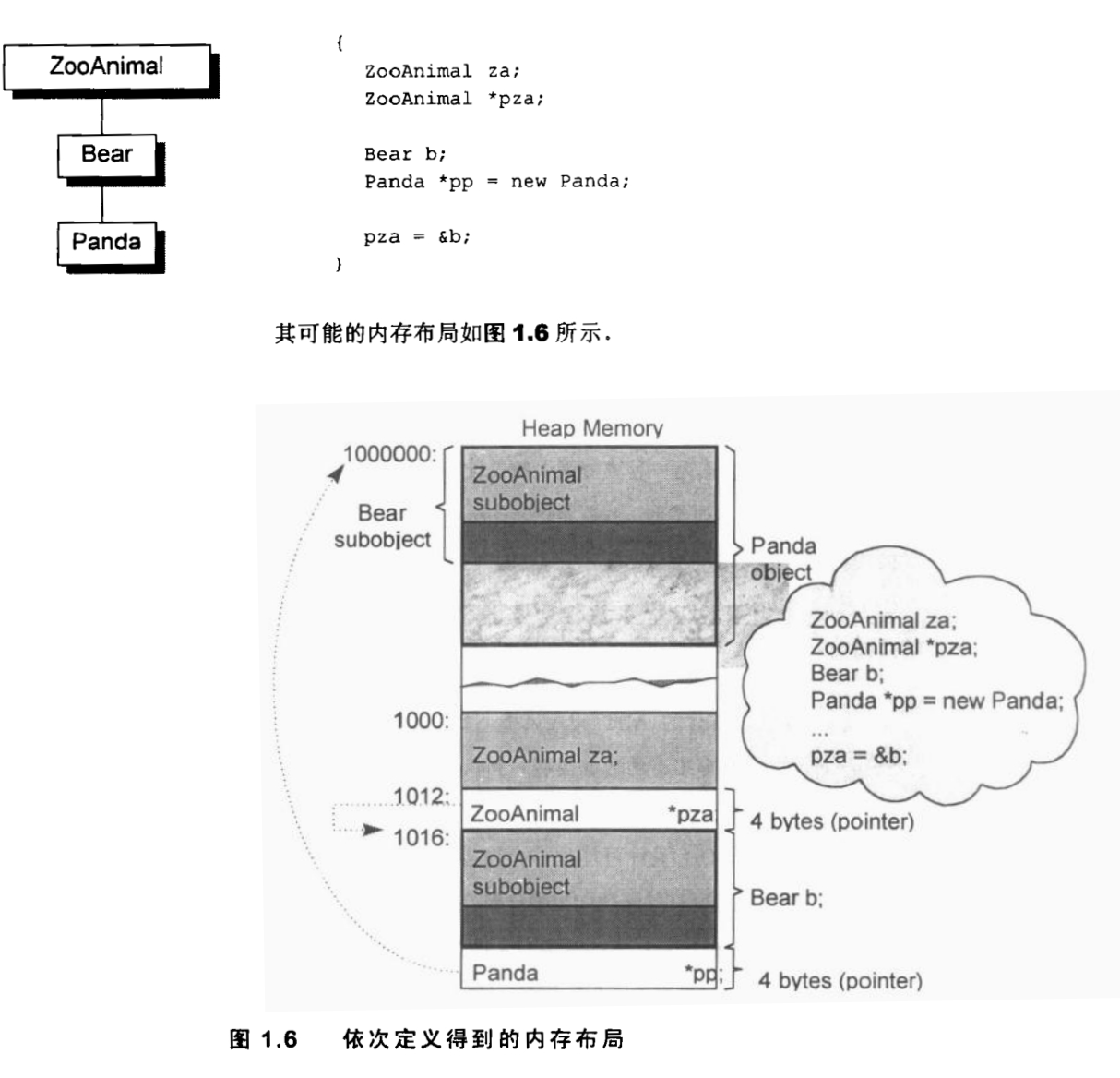
在栈上,我们为每个类型分配的空间是固定长度的。因此对于此时的za来说,如果调用za=*pp,那么编译器必须为其去除所有超出za类型部分的内容,才能将其存储在za的空间中。在这个过程中,甚至连派生类中,和自己相关的虚函数表指针都没法保留(因为保留之后也没有意义,za失去了派生类的所有数据成员,已经失去了能运行派生类虚函数的环境了,即使这个虚函数是从自己这里重写的也一样)。相反,pza,或者ZooAnimal&引用可以保存任何的派生类对象,例如图中的pza=&b,因为这种保存只是修改了指针,改变了对一段内存区域的内容解释方式。
struct Test {
virtual void func() {
cout << "in Test" << endl;
}
};
struct Test2 : public Test {
virtual void func() override {
cout << "in Test2" << endl;
}
};
Test2 t2;
// 只是对内存的重新解释
((Test*)&t2)->func();
// 转型会丢弃所有和派生类相关的内容
((Test)t2).func();
Test t1=t2;
// 此时虚函数表已经是普通的Test的虚函数表了
t1.func();
(&t1)->func();
// 输出是
// in Test2
// in Test
// in Test
// in Test
类型转换
了解了内存布局之后,C++提供的四种类型转换就很明显。
| 转换 | 发生时间 | 作用 | 备注理解点 | | — | — | — | | static_cast | 编译期 | 用于相关的类型之间,或继承下的向基类转换,是C++风格的类型强转 | 无关的类型,或者下行,会报不存在转换 | | reinterpret_cast | 编译期 | 用于不相关的类型之间,对数据做重新解释 | | | const_cast | 编译期 | 移除const | | | dynamic_cast | 运行期 | 对指针和引用,利用类型的RTTI信息(虚表),能判断类型转换是否正确 | 必须是有多态(虚函数)、必须 |
可以看如下的一些示例代码
#include <iostream>
using namespace std;
struct Test {
int a;
int b;
virtual ~Test() {}
};
struct Middle {
int d;
virtual ~Middle() {}
};
struct Test2 : public Middle, public Test {
int c;
virtual ~Test2() {}
};
int main(){
// 也回忆一下此时类型的大小
cout << sizeof(Test) << endl;
cout << sizeof(Test2) << endl;
cout << sizeof(Middle) << endl;
Test2 t2;
t2.a = 1;
t2.b = 2;
t2.c = 3;
t2.d = 4;
Test t1;
t1.a = 0;
t1.b = 0;
// 也是允许的,但会出现警告:不要使用切片(sliced)
t1 = t2;
cout << t1.a << " " << t1.b << endl;
t1 = static_cast<Test>(t2);
cout << t1.a << " " << t1.b << endl;
Middle m1;
m1.d = 0;
cout << m1.d << endl;
// dynamic_cast可以将已截断的指针恢复回来
m1 = *dynamic_cast<Middle*>(dynamic_cast<Test2*>(dynamic_cast<Test*>(&t2)));
cout << m1.d << endl;
// 但如果是假的指针,是不可能通过dynamic_cast的
cout << std::boolalpha << (dynamic_cast<Middle*>(dynamic_cast<Test2*>(&t1)) == nullptr) << endl;
// 这里会发生空指针解引用异常
m1 = *dynamic_cast<Middle*>(dynamic_cast<Test2*>(&t1));
cout << m1.d << endl;
return 0;
}
和内存布局有关的错误使用
- 虚析构问题,再次参考c++内存分布之虚析构函数
工具
- 在Visual Studio下,可以通过提供的Native Tool,查看内存布局,具体方法是
# 搜索命令,x64或x86 Native Tools Command Prompt for VS 20XX cd /path/to/your/source/ # 将下面的{YourClass}整体替换为你想看的类型 cl /d1 reportSingleClassLayout{YourClass} YourCpp.cppG++有类似的方法,是
g++ -fdump-lang-class -c YourCpp.cpp,不管你有什么疑惑,看一下这个布局,就全明白了