
《Hadoop权威指南(第四版)》读书笔记
目录
在大数据处理领域,Hadoop生态凭借多年的运营,基本上已经成为相关实现的事实标准。本文记录为读书笔记。
学习过程中,主要使用docker封装的hadoop 3.2.1版本。本地调试时,使用Windows10、Hadoop 3.3.0.、winutil 3.3.0。
准备工作
使用docker compose搭建:参考Hadoop
写在前面
Hadoop是由Apache Lucene创始人Doug Cutting创建的。Doug Cutting一直致力于制作强大的搜索系统。他发起了Lucene(1999)、Nutch(2004)、Hadoop(2006)等项目。在发展过程中,Google的三篇论文(GFS、MapReduce、Big Table)起到了决定性的作用,Hadoop可以视为是三篇论文的最佳开源实现。
书中提到的SETI@home。是一个志愿计算项目,鼓励志愿者将自己的CPU的空闲时间利用起来,计算SETI项目分发的天文数据。这些数据往往需要进行几小时乃至几天的运算。和Hadoop的目标场景在多种维度上都有显著区别。
书中提到的一些示例程序,需要有相应的数据。可以从以下参考资料中获得。
- 提取并整理 NCDC 气象数据。在使用ftp匿名登陆时,用户名为anonymous,密码输个邮箱就行。注意需要特殊网络连接(你懂的)。
# 下载2023年全部数据 wget -r -nH ftp://ftp.ncdc.noaa.gov/pub/data/noaa/isd-lite/2023 --ftp-user=anonymous --ftp-password=你的邮箱
Hadoop作为大数据处理生态解决方案。其生态中的各个组件也并不是简单接入就能适用于所有业务场景。在技术选型时,要充分对比各种方案。
书中内容主要基于Hadoop2.X,但截止博客撰写,Hadoop3.x已经大规模使用,具体有如下区别值得注意
- HDFS中使用纠错码EC,代替副本机制,大幅减少存储空间消耗
- 集群节点上限更高(10000+)
HDFS
当数据的大小超过一台独立的物理计算机的存储能力时,就有必要对数据进行分区,并分布存储到网络内的多个计算机上。HDFS就是Hadoop生态中,负责完成这一任务的子系统。全称是Hadoop Distributed File System,有时也称为DFS。
当然实际上Hadoop的文件系统概念是一个抽象概念,只需要实现了FileSystem类的都可以作为其文件系统进行使用。除了HDFS外,还有LocalFileSystem、WebHdfsFileSystem、SWebHdfsFileSystem、HarFileSystem、ViewFileSystem、FTPFileSystem等等。因此虽然主要面向HDFS,但是仍然应当主要面向FileSystem、FileContext这些抽象类/接口进行编程。
HDFS是为专门的场景而设计的,即需要以流式的访问模式,来存取超大文件,并能运行于(相对)廉价的商用硬件集群之上。具体来说,有以下几个特点。
- 目标是支持较多的超大文件,而不是海量的小文件
- 流式数据访问:一次写入、多次读取,会在数据上进行长时间的分析。不要求低时间延迟
- 不要求昂贵的高可靠设备,可以在廉价设备上运行。允许设备故障
- 对多用户,文件任意位置修改等常规的文件系统的功能支持有限(甚至是不支持)
基础指令示例
# 查看HDFS根目录下的所有文件的块信息
hdfs fsck / -files -blocks
# dfs的参数是常规指令
hdfs dfs -ls
hdfs dfs -cat ./output3/part-00000
# 在namenode节点上,将本地磁盘文件/tmp/temp.txt,写入到hdfs(实际上是namenode服务,端口9000)的/user/root/路径下
hadoop fs -copyFromLocal /tmp/temp.txt hdfs://localhost:9000/user/root/temp.txt
# 从HDFS拷贝回本地路径(实际上,在正确配置了core-site.xml之后,是可以省略hdfs://localhost:9000的)
hadoop fs -copyToLocal /user/root/output3/part-00000 /tmp
hadoop fs -mkdir /user/root/test-dir
hadoop fs -ls /
# 查看SequenceFile,将二进制转换为可视字符
haddop fs -text yourSeq.seq | head
HDFS的核心设计有以下几种概念:
- 块:和传统文件系统采用文件为单位存储不同。HDFS采用块来对文件系统进行抽象,块是HDFS对数据进行备份和传输的基本单位。文件的元数据也并不需要和块一同存储。一个块默认128MB。在一个块中可能存储多个文件(多个小文件),也可能由多个块共同构成一个大文件。在实现中,还有如下要点
- 块缓存:对于经常访问的文件,所在的块可被显式的缓存在datanode的内存中,而且是以堆外块缓存的形式存放(off-heap block cache,在JVM管理范围之外的本地内存)。
块的默认大小,也是一个值得思考和优化的数值。过大的块大小会使得参与Map的节点变少(因为有数据的节点变少了),但是过小的块大小又会使对块的寻址时间变长。
- 两类节点(计算机):namenode、datanode
- 管理节点namenode:以命名空间镜像文件和编辑日志文件,存储HDFS文件系统树,直接保存在本地磁盘。另外也会记录每个文件的各个块所在的数据节点的信息(非永久,由datanode上报)。
- 数据节点datanode:HDFS真正存储数据的工作节点,存取数据块,定期向namenode发送自己目前维护的块信息。
- 联邦HDFS:由于namenode管理全部文件的块信息,其很容易受到单机内存的限制。因此HDFS也引入了对namenode的扩展,允许不同的namenode分别管理文件系统树的一部分(比如不同的namenode管理不同的目录)。在这种情况下,因为namenode之间相互独立(不通信),而且datanode上的块是通用的(可能存储任意HDFS路径下的文件),所以datanode需要注册到每一个namenode,以使自己所维护的块信息准确存储到对应的namenode上。
- namenode的容灾方案示例
- 方法一:写本地磁盘的同时,同步原子地写入一个远程网络文件系统NFS
- 方法二:运行一个辅助namenode。具体可以用定期备份、热备等方式。
高可用HA,虽然前文提到了namenode的容灾方案。但是恢复的过程仍然会非常漫长。包括且不限于:将文件系统树加载到内存,重放编辑日志,接收到足够多的datanode的注册。这个过程是冷启动,随着块数的增加而增加。Hadoop2开始,针对该问题引入了活动-备用(active-standby)namenode,在活动namenode失效时,备用会立刻接管。甚至可以根据需要,配置若干个namenode,并由选举产生活动namenode。在这种方案下,活动和备用切换时不会有明显的中断。
HDFS的接口,虽然HDFS提供了HTTP、C等接口,但主要使用应该还是在Java中。值得注意的是,并不是所有文件系统都能支持所有操作。比如文件内容追加FileSystem.append(),就不是所有文件系统都支持的。这一点在调用FileSystem的API时会受到异常。下面是几种使用方式。
// 一个简单的办法是使用URL进行访问,但这需要修改URL的工厂
// 通过设置URL的工厂方法,支持对Hadoop文件系统的URL协议
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
try{
// 访问Windows本地文件系统
// in = new URL("file:///E:/Hadoop/hadoop-3.3.0/data/input/t1.txt").openStream();
// 访问HDFS
in = new URL("hdfs://user/root/output3/part-00000").openStream();
byte[] data= new byte[1024];
in.read(data);
String a=new String(data);
System.out.println("data:"+a);
} catch (Exception e){
e.printStackTrace();
} finally {
IOUtils.closeStream(in);
}
// 一个更通用的办法是使用FileSystem的API
// fs在创建时可以通过配置来获取当前的文件系统(需配置core-slite.xml等)
FileSystem fs = FileSystem.get(job);
OutputStream out = fs.create(new Path("E:/Hadoop/hadoop-3.3.0/data/input/t3.txt"));
try{
// 如当前配置了Windows本地文件系统,输入Windows本地路径
in = fs.open(new Path("E:/Hadoop/hadoop-3.3.0/data/input/t1.txt"));
// 将流式数据输出到标准输出
IOUtils.copyBytes(in,System.out,1024,false);
((FSDataInputStream)in).seek(0);
IOUtils.copyBytes(in,out,1024,false);
((FSDataInputStream)in).seek(0);
IOUtils.copyBytes(in,out,1024,false);
} catch (Exception e){
e.printStackTrace();
} finally {
//
IOUtils.closeStream(out);
}
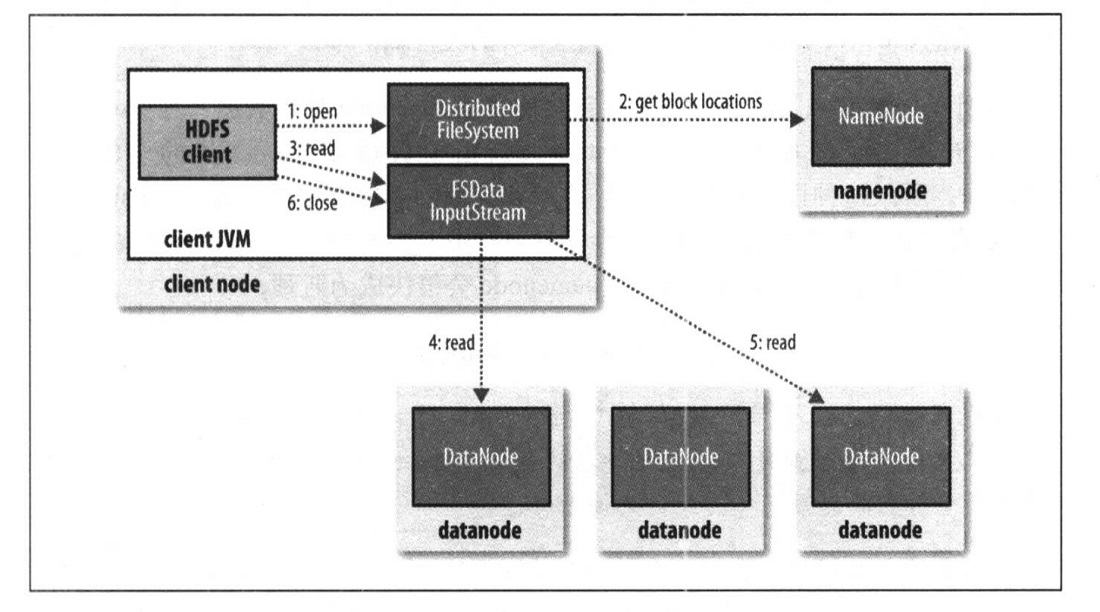
一次对HDFS的读取过程主要有6个步骤,其中最重要的流程就是从namenode读取到所需文件的块信息(块信息存在内存中),并进一步去对应datanode上读取数据,不同的块可以并发去不同的datanode读取。这些过程都是用RPC方式完成的。
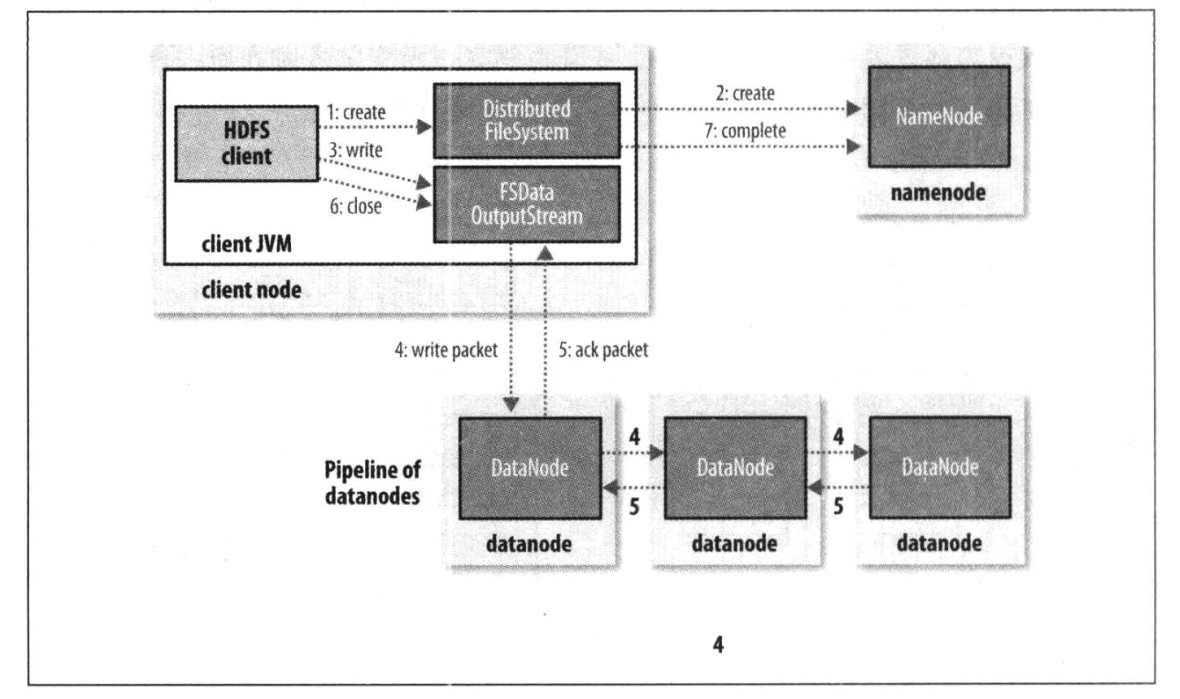
一次对HDFS的写入过程则稍微复杂一些,重点是需要在namenode上创建块信息(要先选择一组最适合的datanode),并在写入完成后更新完善块信息。HDFS客户端只负责将块数据流式的传输给第一个datanode,后续datanode将会链式传递数据(并链式确认)以保证将数据发到所有需要存储块副本的datanode。
数据一致性,作为一个分布式系统,HDFS当然也需要考虑数据的一致性模型。为了性能,HDFS牺牲了强一致性。即当前块正在写入内容不保证立即可见,当前块写入完成后对新的读取可见。
如果对一致性有要求,可以手动调用以下的FileSystem接口。
hflush,立刻刷新写入数据到所有的datanode的写入管道,对新的读取可见。但不保证datanode写磁盘完成。掉电丢失数据。hsync,确保写入磁盘完成。
Yarn
Yarn的全称是Yet Another Resource Negotiator,顾名思义是Hadoop的资源管理系统。Yarn不仅能够为MapReduce提供底层支持,也支持其他的分布式计算模式,如Spark等。
Yarn主要使用两种守护进程:
- 资源管理器Resouce Manager:管理整个集群的资源使用
- 节点管理器Node Manager:每个节点上都会有一个该进程,用于启动并监控节点上的容器
注意!这里的容器对一个执行特定应用程序的进程的抽象。可能是一个单纯的进程,也可能是一个Linux cgroup。这取决于Yarn的配置。
 如图所示是一个典型的Yarn应用提交。客户端将运行请求提交给资源管理器。资源管理器寻找一个合适的节点管理器,并由其创建一个容器,执行Application Master进程。之后则由应用的需求决定,可能直接运行结束,也可以向资源管理器申请更多的节点进行分布式计算(图中的步骤3)。
如图所示是一个典型的Yarn应用提交。客户端将运行请求提交给资源管理器。资源管理器寻找一个合适的节点管理器,并由其创建一个容器,执行Application Master进程。之后则由应用的需求决定,可能直接运行结束,也可以向资源管理器申请更多的节点进行分布式计算(图中的步骤3)。
Yarn的核心功能主要有两部分:资源请求、应用生命期管理、作业调度
- 资源请求:Yarn在决定执行节点时,会考虑数据副本的位置,并尽量满足本地化限制(不需要通过网络传输数据),同时还要满足应用中提出的其他运行时资源限制(比如对内存和CPU的要求)。另外根据应用的编写情况。Yarn可能在运行期为其动态的创建资源,或者在一开始就创建好。
- 应用生命期管理:对于应用的管理,主要有三种模型
- 一个用户作业对应一个应用:MapReduce
- 一个用户作业中的每个工作流对应一个应用,将作业按步骤拆分,方便容器在不同作业之间的重用,以及中间结果的复用:Spark
- 多个用户共享一个长期的应用,这种往往是一些具有专门功能的应用
- 作业调度:只要有作业,就要有调度
- 三种调度器:FIFO、容量、公平
- FIFO:先完成先来的作业
- 容量调度:划分出多个相互独立的队列,并且每个队列分配到一部分独立资源。比如专门留出一部分供小作业使用的资源,以及一个专门为小作业调度的队列。但是这个显然可能出现资源不足的情况,因此有名为“弹性队列”的优化,允许某个队列的作业在资源不够时,从其他队列的空闲资源中,借来一部分资源使用。
- 公平调度:依然可以划分多个相互独立的队列并分配独立资源。当一个队列中到来新的作业时,如果整体没有作业,那它可以直接获得全部资源。但当有其他作业到来时(不论是不是一个队列),会等待它让出一部分资源,并启动新的作业。为了避免等待时间不可控,而且公平调度还支持“抢占”功能。不过抢占并不一定能提高运行效率。因为作业需要被重新计算。
- 延迟调度:如果本地化限制不能满足,也不会立即去其他节点开始作业,而是稍微等待一会儿。避免刚分配了一个没有所需数据的节点,有数据的节点就空闲了的悲剧。
- 三种调度器:FIFO、容量、公平
I/O操作
本节简单记录一下在I/O操作过程中用到的一些实用技术。
数据完整性。Hadoop会对数据传输和存储过程中的完整性进行保证。HDFS会对所有写入的数据都计算校验和,默认是512字节,计算一次CRC32,产生4个字节的校验和。datanode在数据写入、读取、和维护这三个过程中,都涉及到校验和的计算。其中:
- 写入时的校验和:由本次写入的pipeline管线中最后一个datanode负责验证。如果出现不一致,客户端会收到异常。
- 读取时的校验和:客户端对读取到的数据进行CRC校验和计算,并和datanode中存储的校验和进行对比
- 维护:datanode有一个后台进程负责定期对所有数据块进行校验和计算,并记录下数据块的最后一次验证时间,如果发生校验和不一致的情况,则上报损坏报告给namenode,由namenode负责阻断对该数据块的引用,并再创建一个副本以恢复到足够副本数量。
文件压缩。减少存储空间,加快网络传输速度。虽然可以用Java中的codec等方案进行压缩解压缩。但最高效的方式还是使用Native库来进行处理。但是在这个过程需要注意压缩数据的输入分片问题。由于数据是在写入HDFS之前就完成压缩的。如果选用的压缩算法不支持分片/切分,那么在读取数据时,必须从其他节点读取到所有的数据块并拼合才能开始解压缩。这显然会破坏本地化。从这里可以再一次看出,MapReduce最重要的优化手段,就是提高计算的本地化程度。
序列化。Hadoop使用了自定义的序列化反序列化方案,即Writable接口,其提供读取和写入二进制流的功能。Hadoop实现了很多满足接口的类型,涵盖了从数字、字符串、Object、Map等多种多样的数据结构。如果有自定义二进制内容的需求,也可以自定义实现一个。
实际上,Hadoop并不限制序列化方案。只要你想,你可以替换为其他序列化框架。
文件操作。对于一些希望持久化存储二进制数据到磁盘的场景。Hadoop提供了更高层次的容器:
- SequenceFile:SequenceFile可以添加键值对儿作为记录,只要是可以被序列化的都可以作为记录内容,并且可以对记录进行压缩。为了放置读取时位置混乱,SequenceFile每隔一段距离就会有一个同步标记。
- MapFile:是已经排过序的SequeneFile,可以按键进行查找,有索引(每隔128个键)。准确的说是两个SequenceFile,一个是主文件,一个是索引文件。在MapFile的基础上,还有SetFile、ArrayFile、BloomMapFile(对稀疏文件使用的,布隆过滤器版本)。
- 按列存储:SequenceFile和MapFile都是按行存储的。在一些基于Hadoop的组件中,也有一些使用面向列数据的存储方案,即存储每一行的第一列的值,然后存储每一行第二列的值。
// 一个SequenceFile的使用示例
private static final String[] DATA = {"One,two,buckle my shoe", "Three,four,shut the door", "Five,six,pick up sticks", "Seven,eight,lay them straight", "Nine,ten, a big fat hen"};
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
System.out.println("hello world");
String uri = "file:///E:/Hadoop/hadoop-3.3.0/data/seq.txt";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
IntWritable key = new IntWritable();
Text value = new Text();
SequenceFile.Writer writer = null;
// CreateWriter在3.x版本中有更新,推荐用Option方式传递配置
SequenceFile.Writer.Option optFile = SequenceFile.Writer.file(path);
SequenceFile.Writer.Option optKey = SequenceFile.Writer.keyClass(key.getClass());
SequenceFile.Writer.Option optValue = SequenceFile.Writer.valueClass(value.getClass());
try {
// 创建SequenceFile
writer = SequenceFile.createWriter(conf,optFile,optKey,optValue);
for (int i = 0; i < 100; i++) {
key.set(100 - i);
value.set(DATA[i % DATA.length]);
// 当前写入长度,键值
System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key, value);
// 继续写入
writer.append(key, value);
}
} finally {
// 关闭流
IOUtils.closeStream(writer);
}
}
MapReduce
最经典的计算模型,官网的一段例子可以很好的入门理解。
// 最经典的分词统计算法
public class WordCount {
// Map和Reduce的含义和函数式编程类似
// Map阶段,产生新的值,将每一个词映射为数字1
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
// 输出为下一阶段的key和value
context.write(word, one);
}
}
}
// Reduce阶段,若干个值生成一个值
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
// 上一阶段的Key会合并到一个,遍历其所有value
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
// 默认就是文本输入形式(读取输入文件夹的所有文件)
// job.setInputFormat(TextInputFormat.class);
// job.setOutputFormat(TextOutputFormat.class);
// 三个阶段:Map、Combine、Reduce。相邻的两个阶段的输入输出要匹配
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class); // 使用combine需要满足结合律
job.setReducerClass(IntSumReducer.class);
// 设置最终的输出的key、value类型,必须和最终的Reduce的输出类型匹配
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置(多个)输入,设置输出
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
原理概述
- Hadoop将一次计算的完整执行,称作Job(作业),它包括了输入数据、MapReduce程序,以及各种配置信息。运行期,Hadoop会将Job分为若干个任务Task来执行,具体就是各类Map任务和Reduce任务。它们将会分布在不同的节点上,由Yarn进行调度执行。
- 对于海量的输入数据,Hadoop会将其切分为登场的小数据块,称为输入分片(input split),在每个分片上构建Map任务。分片的大小划分是一个优化要点,过大的分片可能会造成计算负载的不均衡,过小的分片又会造成管理分片和构建Map任务的时间增加。
- 数据本地化优化是MapReduce最重要的优化之一。也就是说Hadoop应该在由输入数据的HDFS节点上运行对应的Map任务,而不是使用宝贵的网络通信资源。即使发生了必须在无输入数据的节点上运行程序的情况(比如有数据节点任务排满),也应当按照优先同一机架、同一机房等顺序,就近处理。
- MapReduce的每一步都会落盘,但Map任务产出的一般将会只写入到本地硬盘,而非HDFS,这是因为Map产生的一般都是中间结果,而中间结果在最终会被删除,没有必要做分布式存储。如果该节点在返回计算结果前失败,Yarn调度其他节点重新计算。
- reduce输出的最终结果会落HDFS,其第一个副本就存储在reduce任务所在的HDFS节点中。
- 多个reduce任务时,map到reduce的数据传递称为混洗shuffle。在这个阶段,每一个map输出都会按键切分为若干分(和reduce节点数量一致),并分给各个reduce节点。
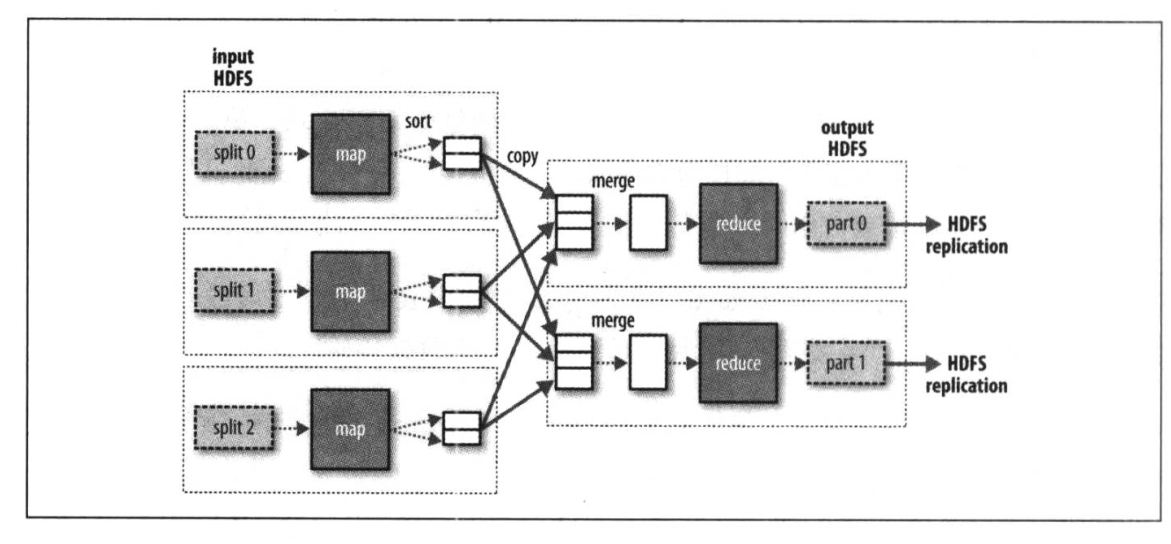
- 对于无reduce的任务,各个map完全并行,而且输出数据也直接落hdfs。
- combiner是在map任务之后的一个优化任务,目的是削减map任务节点和reduce任务节点之间数据传输量。它的思路也很好理解,例如对于求极值的问题,在map之后,可以立刻在原节点内,对所有具有相同的键的键值对求一次极值,此后对于一个键,只需要给reduce节点传递一个值。而不是坐等把所有键值都传给reduce去处理。
MapReduce也可以通过Hadoop Streaming的方式进行实现。尤其是对于一些轻量级的MapReduce开发需求,使用Streaming可能更简单。Streaming的原理说到底,就是用标准输入输出作为数据传递的管线,代替原先在Java中设置的Map和Reduce之间的数据传递,由hadoop来完成对整个流程的控制。主要的有点就是不限语言,只要它能处理标准输入输出就行。下面是一段Streaming的最简单的例子。
# 提交streaming任务,mapper用cat,reducer用wc,最终将会对所有文件的数据进行wc
mapred streaming -input input -output output3 -mapper /bin/cat -reducer /usr/bin/wc
在MapReduce开发中,有一些技巧值得考虑
- 使用xml配置文件对应用进行配置,而不是硬编码
Configuration conf = new Configuration(); conf.addResource("configuration-1.xml"); // 同名的属性会覆盖 conf.addResource("configuration-2.xml"); - 对Mapper和Reduce编写单元测试。
存疑:MRunit库已经很久不维护了
- 在本地的伪分布式环境中,并在小型数据集上完整执行程序。见一些坑
- 对任务做一定程度的性能测试,提高MapReduce的性能,这些调优包括但不限于:均衡mapper/reducer的数量和任务量(不要启动过多的mapper/reducer),通过combiner减少中间数据传输,对map的输出进行压缩,自定义序列化,调整shuffle过程。
- 编写更多种类的作业,来组合完成复杂的任务。而不是写出一个非常复杂的作业,来完成单一的业务。
当各种Hadoop作业出现组合时,构成所谓的工作流。工作流引擎就是负责处理作业之间的依赖关系,并正确的调度作业运行。不同类型的任务都可以组合在一起(MapReduce、Hive等)
工作流程
在Yarn章节中,已经介绍了一个通用的Yarn作业的基本工作流程。本节针对MapReduce做一些特别的说明。
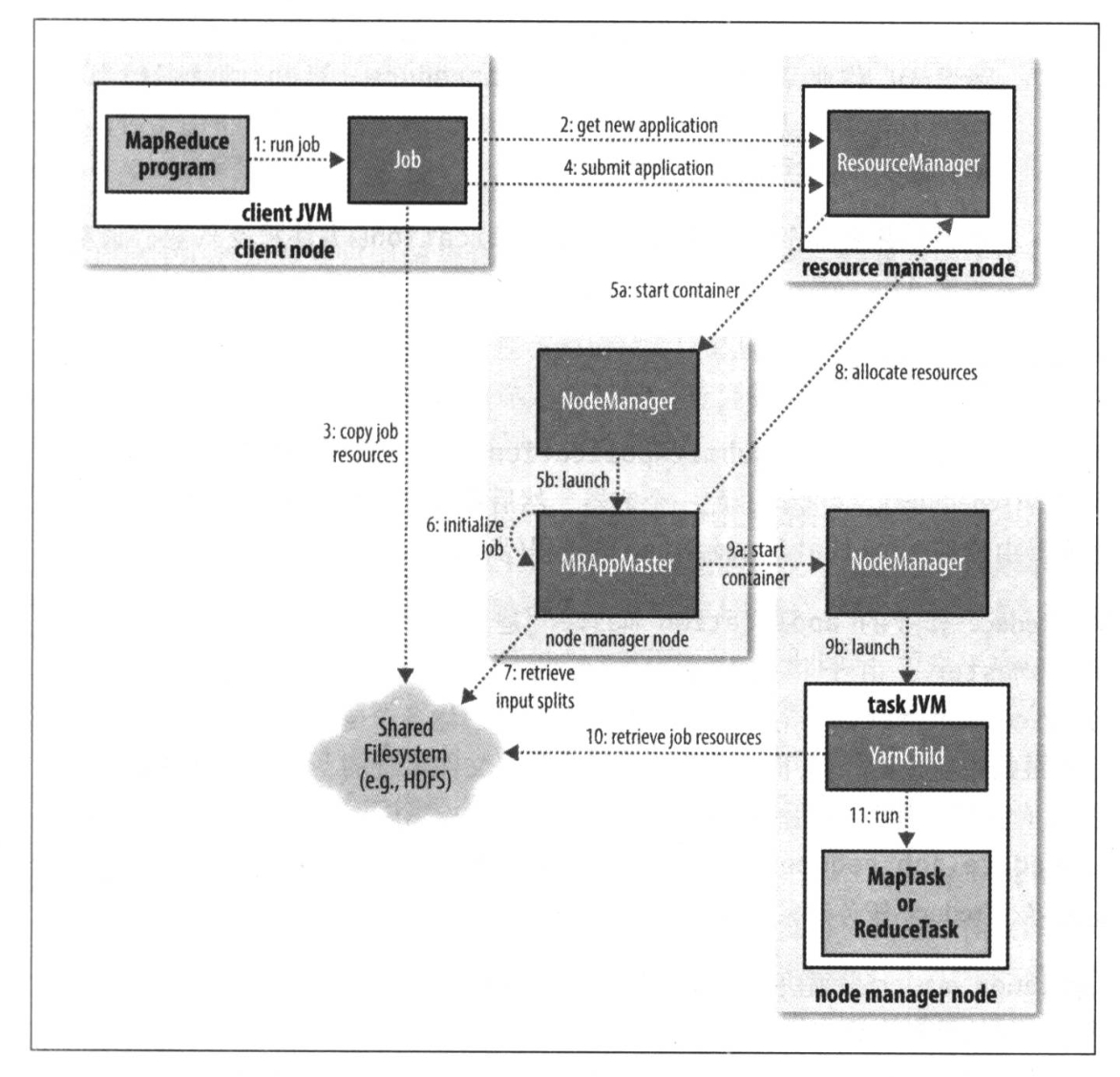
图中流程分别是
- 第1步:启动作业
- 第2~4步:JobSummiter进行实际的作业提交,请求应用ID,检查输入输出是否正确,将资源(程序/配置)拷贝到共享文件系统,正式提交运行
- 第5~9步:作业的初始化,这一阶段相对比较复杂
- Yarn调度器在一个节点上分配一个容器,作为Application Master
- Application Master决定参与此次MapReduce作业的各个任务节点
- 如果任务是小任务(uberized),就和自己在一个JVM里直接执行。
- 否则,分别为Map任务和Reduce任务发出请求,向Yarn调度器申请资源。优先分配Map,Map优先数据本地化。Reduce则没有这个本地化的限制。
- 在执行之前,为所有参与计算的节点,获取到所需的输入数据分片、运行程序、配置等
- 第10步:执行
- 执行阶段可能有多个任务副本(根据配置),他们执行同一套输入。协议将保证只会有一个输出被接收。
- 对于异常情况,由于大家在不同的JVM中运行,因此并不会影响到整体作业。失败的任务重新启动即可。
关于Streaming,Yarn会为其专门启动一个Map、Reduce的Java程序,但是会将其输入输出,分别以标准IO的方式,绑定给对应的外部进程。对Yarn来说是一样的。
虽然对程序执行状态的观察并不容易。但是MapReduce还是尽力为用户提供了相应的状态以供查询。
- 状态分类:每一个任务的状态(运行中、成功、失败)、Map/Reduce进度、用户可控制的作业计数器、用户代码中的状态消息或描述
- 状态通信方式:map任务、reduce任务,和Application Master进行通信。定期报告进度和状态
- 提供了作业完成通知选项供配置
生态
- HBase和Hive
- ZooKeeper
- Spark
- Flink
- Avro
- Flume
- Sqoop
- Pig
- Solr
- 其他
一些坑:
- Hadoop执行程序是需要打包程序,上传到集群上执行的,因此对于MapReduce程序,如果想要调试的话,是不能无配置就直接在本机调试(没有那些Jar)。但本地调试还是很重要的,参考Windows 10安装Hadoop 3.3.0教程。其中关于四个xml文件的配置如下
xml <!-- core-site.xml --> <configuration> <property> <name>fs.default.name</name> <value>hdfs://0.0.0.0:19000</value> </property> </configuration> <!-- hdfs-site.xml --> <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///e:/Hadoop/hadoop-3.3.0/data/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///e:/Hadoop/hadoop-3.3.0/data/data</value> </property> </configuration> <!-- yarn-site.xml --> <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> </configuration> <!-- mapred-site.xml --> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value>%HADOOP_HOME%/share/hadoop/mapreduce/*,%HADOOP_HOME%/share/hadoop/mapreduce/lib/*,%HADOOP_HOME%/share/hadoop/common/*,%HADOOP_HOME%/share/hadoop/common/lib/*,%HADOOP_HOME%/share/hadoop/yarn/*,%HADOOP_HOME%/share/hadoop/yarn/lib/*,%HADOOP_HOME%/share/hadoop/hdfs/*,%HADOOP_HOME%/share/hadoop/hdfs/lib/*</value> </property> </configuration>- winutil必须复制到Hadoop的bin目录下
- 只是想在IDEA中调试运行的话,不需要真正启动Hadoop。配置环境变量(HADOOP_HOME、Path中添加bin、sbin)即可。main函数中连配置都不需要改。
- 3.3.0以前会出现文件操作权限问题,参考Install Hadoop 3.2.1 on Windows 10 Step by Step Guide
- 如果真的想要在Windows上运行Hadoop,需要以管理员身份运行start-all.cmd
- Hadoop的各类依赖在Maven中可能会产生依赖冲突,需要通过插件进行exclude解决。
- 但有些只是运行时警告,无所谓。
参考资料
《Hadoop权威指南 第四版(修订版&升级版》