
《现代C++教程》:读书笔记
目录
从C++11开始,C++开始加速向一门更现代的语言进化。很多需求都有了更优秀的写法来替代原来的技巧。
本节内容是读书笔记,而且该书并未完善完成,可结合C/C++:标准篇观看。
标准更迭
- 实际上C++并不是C的超级,从一开始的标准就无法完全做到。在代码中应当使用宏和
extern来严格标记混合使用的位置。参考C和C++互操作。 - 在编写代码的过程中,注意允许使用的C++标准,给IDE或编译器传递正确的选项。
可用性优化
-
一些很熟悉的C++11特性一笔带过:
- 区间迭代语法:
for(auto &t:vec) - 类型别名模板,类型别名。即推荐用
using代替typedef// 弥补typedef只能对类型指定别名,不能对模板指定别名的缺陷 template<typename T> using MyTemplateAlias = MyTemplate<std::vector<T>>; // 无法通过编译,因为模板并不是类型,模板是用来生成类型的 // typedef MyTemplateAlias ... // using 同时也能给函数指针的别名带来更好的可读性 using MyFunc = int(*)(void *); // 相比之下,使用typedef可读性较差 typedef int (*MyFunc)(void *); MyFunc f = [](void*) ->int { return 0; }; - 变长参数模板,函数模板、类模板都可用。解包可通过递归、模板展开,支持
sizeof...(args)获取变长参数数量// Magic可接收0,1,2...个模板参数 template<typename ...Ts> class Magic; // 变长参数函数模板 template<typename... Args> void log(Args... args); // C++11中用递归模板函数,需要提供两个模板 template<typename T, typename...Args> void log(T v, Args... args) { std::cout << v << std::endl; log(args...); } // 该模板用于结束递归 template<typename T> void log(T v) { std::cout<< v << std::endl; } // C++17中由于出现if constexpr,因此可以在一个模板中完成 template<typename T0, typename... T> void printf2(T0 t0, T... t) { std::cout << t0 << std::endl; // 在if constexpr出现之前,if无法在编译期进行判断 if constexpr (sizeof...(t) > 0) printf2(t...); } - 委托构造,允许构造函数调用另一个构造函数
- 继承构造,对于构造函数继承的情况,允许通过
using直接继承。 - 显式虚函数重写,添加关键字
override,final,从而可以对虚函数的重写进行显式控制。class A { public: virtual f(); virtual h() final; } class B: public A{ virtual f() override; virtual f(int) override; // 非法,不存在该虚函数可供重写 virtual h(); // 非法,基类中已声明为final } - 显式禁用默认函数,
=delete,显式使用默认函数=default - 强枚举类型:
enum class - 智能指针:
unique_ptr、shared_ptr、weak_ptr
- 区间迭代语法:
-
constexpr:指示编译器该表达式、函数,需要在编译期被编译为常量表达式。有以下几点值得注意constexpr和const在语义上的区别,前者说明(可能)是一个编译期常量表达式,后者说明是一个不可修改的常量(但其值则可能是运行期给出)。但有一个大的区别const char*说明字符串不可变,指针可变,是指向常量的指针。而如果是constexpr char* pc,则是字符串可变,指针pc不可变,是常量指针。- constexpr对指针和引用的修饰要求很严格。必须是运行时具有固定地址的(全局变量、静态变量),或者是nullptr。
constexpr修饰函数,仍然允许在运行期求值,但是不能有副作用调用(比如调用cout输出)。就是说该函数应当保证如果输入是常量表达式,那么能够在编译期也获得常量表达式。- 修饰构造函数,用于说明类型可以成为可用于常量表达式的对象。当然并不限制成为一个运行期才确定的对象实例(和修饰函数的要求相同)
- 在C++11初次引入时,常量表达式内可以递归,但仍不能使用循环、分支、定义局部变量等简单语句。从C++14开始允许使用。
constexpr用于定义变量时,要求变量的值必须是编译期常量表达式。- C++17开始,支持
if constexpr,可以尝试在编译期提前决定分支判断,和函数定义不同,此时的条件表达式必须具备编译期常量结果。而且注意如果在不同分支返回不同类型的数据,最好让分支位于完整的if/else作用域内,见下面的例子。// 以下代码可能会报错(看实例化的具体需求) // 如果报错,会提示所有返回表达式必须推到为相同类型 template<typename ...Args> auto add(Args... nums){ if constexpr(sizeof...(nums)==1){ return 1; } return "not 1"; } add(1); // 一定报错 // 此时函数内相当于 { return 1; return "not 1"; // 虽然不会被执行,但是无法通过编译 } add(1,3); // 如果只有这一行,不会报错 // 此时函数内是 { return "not 1": // 第一个if被编译期删除掉了 } // 正确的做法是完整的分支 template<typename ...Args> auto add(Args... nums){ if constexpr(sizeof...(nums)==1){ return 1; } else { return "not 1"; } }
-
允许在
if/switch语句作用域内定义临时变量,例如// 先定义,以 ; 分割 // if(Type t; boolean statement) if (const std::vector<int>::iterator itr = std::find(vec.begin(), vec.end(), 3); itr != vec.end()) { *itr = 4; } -
初始化列表
std::initializer_list<>,从C++11开始,为了给类初始化提供近似于POD类型的写法,提出的初始化列表。这使得具有支持初始化列表构造器的类型,可以和POD类型一样,使用{}进行初始化,例如class MyClass { public: MyClass(std::initializer_list<int> list) { /* ... */} MyClass(std::initializer_list<int> list, int append) {/* ... */} // 构造函数调用优先级弱于初值列 MyClass(int a,int b) {/* ... */} MyClass() {/* ... */} } int a[]={1,2,3,4}; MyClass myClass = {1,2,3,4}; // 初始化列表也可以直接通过类似构造函数的方式调用 MyClass myClass2 {1,2,3,4}; // 可以混合 MyClass myClass3 {{1,2,3,4},1}; // 优先使用初值列,实际上带有初值列的构造函数的类型,其大括号构造方式会默认劫持所有{}的构造调用 MyClass myClass4 {1,2}; // 因为存在无参构造函数,此时以下两种都会调用无参构造 // 如果没有无参构造,前者会编译失败,后者会调用到初始化列表的构造 MyClass myClass5,myClass6{}; // 另外注意无参构造函数用圆括号初始化会导致一个歧义,此处声明了一个新函数,而非调用了MyClass构造函数 MyClass myClass(); // 此外,C++11中初始化列表展开还能做到对变长参数的展开 // 不过该写法不如C++17支持的折叠表达式简洁 template<typename T, typename... Ts> auto printf3(T value, Ts... args) { std::cout << value << std::endl; // 理解...参数展开可以在复杂表达式中展开 // 即args...是普通展开,也可以用expr(args)... // 编译器会为其扩展为expr(args0),expr(args1),... // 理解逗号表达式的计算规则 // (void)转型消解对未使用的初值列表的警告 (void) std::initializer_list<T>{([&args] { std::cout << args << std::endl; }(), value)...}; }对于使用圆括号构造,大括号构造的优劣对比,以及使用场景,请参考C++创建对象时区分圆括号( )和大括号{ }。总而言之,如果一个类型没有使用初始化列表的构造函数,那么可以无脑使用大括号,它相对更安全(避免默认的数据窄化,以及无参构造的歧义)。但如果具备初始化列表,则会被初始化列表的劫持,此时仍然需要用圆括号来指定其他类型的构造。 初始化列表展开,可参考知乎回答。
-
结构化绑定,这一功能主要完善了C++11开始拥有的
std::tuple,从C++17开始,可以自动对元组进行解包,例如// 拷贝自原书 std::tuple<int, double, std::string> f() { return std::make_tuple(1, 2.3, "456"); } int main() { // 自动解包,绑定tuple内容 auto [x, y, z] = f(); std::cout << x << ", " << y << ", " << z << std::endl; std::map<int, int> myMap; myMap[1] = 2; myMap[2] = 4; // 自动绑定字典键值结构(原来的写法只能获得键值迭代器,再用first/second来获取键/值) for (const auto& [key, val] : myMap) { cout << key << " " << val << endl; } return 0; } -
类型自动推导,
auto和decltype,其中auto用于对变量类型进行类型推导。用于对变量的定义和声明。decltype用于对表达式进行类型推导,其结果可以进一步用于变量定义、或者模板类型计算 同时,在C++11、C++14都对返回值类型推导做了一定优化,逐渐让返回值的类型推导更自动化,例如
// C++11之前,虽然T、U可以自动推导,但是R必须由用户给出 template<typename R, typename T, typename U> R add(T x, U y) { return x+y; } // C++11,允许在函数签名处用尾返回类型,将返回类型后置(更像一个现代语言) // 但是这种语法还是很丑陋 template<typename T, typename U> auto add2(T x, U y) -> decltype(x+y) { return x + y; } // C++14,直接优化到位 template<typename T, typename U> auto add3(T x, U y){ return x + y; }从C++14起,编译器还提供了对带有封装的返回类型进行推导,例如
std::string lookup1(); std::string& lookup2(); decltype(auto) look_up_a_string_1() { return lookup1(); } decltype(auto) look_up_a_string_2() { return lookup2(); } -
折叠表达式:C++17开始对于主要的32种二元运算符,编译器支持将变长参数直接展开。展开表达式依然可以是一个复杂表达式。这个特性大大提高了变长参数的易用性。下面是一些示例
template<typename ... T> auto sum(T ... t) { // 无初值的左、右展开 int rightExpansion = (t + ...); // t0 + (t1 + (...)) int leftExpansion = (... + t); // ((t0 + t1) + ... ) // 有初值的左、右展开 // 初值包/参数包内运算符优先级需要高于转型,否则要添加括号,如(1 * 2) int initRight = (t + ... + (1 * 2)); // t0 + (t1 + ... + (1 * 2)) int initLeft = ((1 * 2) + ... + t); // ((1 * 2) + t0) + ...) return 0; } // 借助折叠表达式,可以很方便的一系列处理可变长的相同操作 template<class T, class... Args> void push_back_vec(std::vector<T>& v, Args&&... args) { // 用折叠表达式对所有参数检查是否是可构造的 // 这里的参数包甚至是一个模板元运算 static_assert((std::is_constructible_v<T, Args&> && ...)); // 用折叠表达式push_back (v.push_back(args), ...); } // 结合折叠表达式和泛型lambda auto test = [](auto ...data) { // 很有趣的现象,如果这里是引用捕获,会造成后变长参数列表data2覆盖data的值,发生错误 return [=](auto ...data2) { std::string sum = ((std::to_string(data) + " ") + ...); sum += " | "; sum += ((std::to_string(data2) + " ") + ...); std::cout << "in lamda lamda: " <<sum << std::endl; }; }; test(-1,-2,-3)(1,2,3,4); -
非类型模板参数推导,允许使用
auto指示编译器推导非类型模板参数的类型,形如template <auto value> void foo() { std::cout << value << std::endl; return; }
函数对象和Lambda表达式
从C++11引入lambda表达式,其基本形式如
[捕获列表](参数列表) mutable(可选) 异常属性 -> 返回类型 {
// 函数体
}
在C++14,又为其补充了表达式捕获,使其拥有了对右值的捕获能力,示例如下
auto important = std::make_unique<int>(1);
// 在之前的情况下,因为只能捕获值或引用,此时独占智能指针important无法被捕获
// C++14允许表达式捕获,这样就可以使用右值
auto add = [v1 = 1, v2 = std::move(important)](int x, int y) -> int {
return x+y+v1+(*v2);
};
std::cout << add(3,4) << std::endl;
此外,C++14还支持了泛型lambda,这一特性在C++11中并不支持,其写法就是使用auto对参数进行类型推导,例如
auto add = [](auto x, auto y) {
return x + y;
}
值得注意的是,如果lambda表达式内部想要递归,则不能用auto自动推导lambda表达式的类型,需要手动指定,例如
function<int(int,int)> doSth = /*..递归调用doSth..*/。
Lambda表达式的本质是一个很像函数对象的类类型对象(闭包对象)。而且当捕获列表为空时,Lambda表达式还能够和函数指针进行转换。为了协调统一这些概念,C++11开始引入了函数对象概念,即std::function。
函数对象统一了所有的可调用类型,可以更安全方便的对函数、函数指针等可调用内容进行复制存储调用。在此基础上又提供了很多实用的工具,如绑定函数调用参数的bind / placeholders,例如
void foo(int a, int b, int c) {
cout <<"foo: " << a << " " << b << " " << c << endl;
}
int main() {
// 第一个参数用占位符暂时代替,给出了后两个参数
auto fooBind = bind(foo, placeholders::_1, 1, 2);
// 此时只需要传入1个参数,也就是_1位置的占位符
fooBind(3);
// 占位符数量和编号和正式调用时的参数相对应
auto fooBind2 = bind(foo, placeholders::_1, 1, placeholders::_2);
fooBind2(2,3);
// 也可以使用同一个占位符
auto fooBind2_dup = bind(foo, placeholders::_2, 1, placeholders::_2);
fooBind2_dup(2,3); // 输出为3 1 3
return 0;
}
容器
本章节主要记录一些容器的使用习惯推荐
array:在数组长度固定的情况下,用array代替传统[]和vector。- 初值列可用于对关联容器的初始化,例如
std::unordered_map<int, std::string> u = { {1, "1"}, {3, "3"}, {2, "2"} }; - C++17引入的实用工具:
variant、optional、anyany:类,存储任何可复制构造类型的对象、内置类型,通过any_cast进行转型并访问。optional:类模板,任意时刻可包含一个值,或者为空。variant:类模板,类型安全的联合体。其构造函数有相对复杂的语法,参考,基本示例如// 用 std::string{"ABCDE", 3}; 初始化第一个可选项类型 // 理解代码需联系初值列和参数展开 std::variant<std::string, std::vector<int>, bool> var{ std::in_place_index<0>, "ABCDE", 3}; assert(var.index() == 0); std::cout << std::get<std::string>(var) << std::endl; // "ABC"- 工具:
std::get:get对多种类型都有重载std::in_place, std::in_place_type, std::in_place_index, std::in_place_t, std::in_place_type_t, std::in_place_index_t:一系列构造指示,用来说明将一个值作为哪个类型选项来构造variant
- 元组
- 基本用法:
tuple、make_tuple,拆包std::get<>()、std::tie()。但是get<>有一个重大的缺点就是其访问的内容的下标或类型是模板参数,需要在编译期决定,例如auto t = std::make_tuple(1,2.2,'3'); auto t1 = std::get<0>(); // 当使用类型get时,要求元组中没有重复类型的元素 auto td = std::get<double>(); std::tuple_cat:元组合并std::tuple_size<>::value:获取利用类型萃取元组大小- C++17引入了
variant<>,提供了同时容纳多种类型的变量存储能力,可以理解为更安全的union。而且借助variant能进一步提高元组的运行期访问能力,例如。template <size_t n, typename... T> constexpr std::variant<T...> _tuple_index(const std::tuple<T...>& tpl, size_t i) { if constexpr (n >= sizeof...(T)) throw std::out_of_range(" 越界."); // 利用递归,找到i==n的情况,并原位构造variant,且该值构造为第n个variant选项 if (i == n) return std::variant<T...>{ std::in_place_index<n>, std::get<n>(tpl) }; return _tuple_index<(n < sizeof...(T)-1 ? n+1 : 0)>(tpl, i); } template <typename... T> constexpr std::variant<T...> tuple_index(const std::tuple<T...>& tpl, size_t i) { return _tuple_index<0>(tpl, i); }
理解元组主要是理解它的类型和值,C++的元组之间,不同模板参数的元组完全是不同的类型。
- 基本用法:
并行和并发
C++引入的几个基本类型
-
thread:线程 -
mutex:基础互斥锁lock_guard:离开作用域自动释放unique_lock:离开作用域自动释放,也可手动提前释放/再上锁
-
future:访问一个异步操作的结果,通过std::async、std::packaged_task或std::promise创建。在调用get/wait以及析构时会阻塞当前线程,以等待结果。package_task<>:包装一个函数,是可调用对象,本身并不具备开辟新线程的能力。std::async:异步的运行一个函数(也可以选择在当前线程中执行),还可以选择惰性求值。std::promise:一次性使用的,存储值、异常的类型。是更方便的并发同步、数据同步工具类型。通过promise推送数据,future获取消息。
三种类型的功能各不相同,但都具有创建future的能力。想传值用promise,想自定义包装用packaged_task,想无脑异步用async。 示例代码
// 拷贝自cppreference // 来自 packaged_task 的 future std::packaged_task<int()> task([](){ return 7; }); // 包装函数 std::future<int> f1 = task.get_future(); // 获取 future std::thread(std::move(task)).detach(); // 在线程上运行 // 来自 async() 的 future std::future<int> f2 = std::async(std::launch::async, [](){ return 8; }); // 来自 promise 的 future std::promise<int> p; std::future<int> f3 = p.get_future(); std::thread( [&p]{ p.set_value_at_thread_exit(9); }).detach(); std::cout << "Waiting..." << std::flush; f1.wait(); f2.wait(); f3.wait(); std::cout << "Done!\nResults are: " << f1.get() << ' ' << f2.get() << ' ' << f3.get() << '\n'; -
condition_variable:条件变量。条件变量需要和锁一同使用。消费端在wait时自动释放锁,唤醒后自动获取锁。生产端用notify_one / notify_all控制唤醒。下面是一个交替打印的例子。取自力扣交替打印题解class FooBar { private: int n; mutex mtx; condition_variable cv; bool foo_done=false; public: FooBar(int n) { this->n = n; } void foo(function<void()> printFoo) { for (int i = 0; i < n; i++) { unique_lock<mutex>locker(mtx); cv.wait(locker,[&](){return foo_done==false;}); printFoo(); foo_done=true; cv.notify_one(); } } void bar(function<void()> printBar) { for (int i = 0; i < n; i++) { unique_lock<mutex>locker(mtx); cv.wait(locker,[&](){return foo_done;}); printBar(); foo_done=false; cv.notify_one(); } } }; -
原子变量,先来看一段也是交替打印的例子
class FooBar { private: int n; atomic<bool> flag=true; // volatile bool flag=true; public: FooBar(int n) { this->n = n; } void foo(function<void()> printFoo) { for (int i = 0; i < n; i++) { while(!flag.exchange(false)) std::this_thread::yield(); // printFoo() outputs "foo". Do not change or remove this line. printFoo(); } } void bar(function<void()> printBar) { for (int i = 0; i < n; i++) { while(flag.exchange(true)) std::this_thread::yield(); // printBar() outputs "bar". Do not change or remove this line. printBar(); } } };
原子变量提供的api也比较丰富,exchange、load、store、compare_exchange_weak/strong、fetch_add、wait、notify_one/all。
在C++11之后,为了进一步提高性能,也开始出现了对无锁编程的支持,具体是用原子变量和内存顺序模型两个内容来完成的。具体原理还会牵扯到缓存一致性等问题,可以详细参考阅读原子操作与内存模型/序/屏障、程序员的自我修养(⑫)、C++ 多线程:内存模型(std::memory_order)、内存模型和atomic——理解并发的复杂性 。下文暂时不再考虑缓存的问题(毕竟对软件透明),只对C++编程中需要了解的内存顺序模型做一个总结。
原子变量atomic<>。类模板,原子类型,通过CPU支持的CAS指令等原子操作去修改变量。但并不是每个CPU平台都能支持真正的无锁,可以用is_lock_free进行判断。
有了原子变量,还不能直接把原子变量当成一种互斥或同步的手段,这是因为现代编译器、CPU,都有可能会对指令重排。编译器的重排可能出于指令优化的考虑,CPU的重排则可能是出于执行速度的考虑,避免CPU空转。因此任何操作,尤其是在原子操作附近的临界区中的操作,并不能保证执行顺序和代码顺序是一致的。表现上就是,这一段代码单线程执行不会有问题,即使发生了重拍,编译器和CPU也保证对于单个线程内部的指令,保持正确依赖关系下的重拍。但是如果在多线程环境下,其他线程内看似没问题的重拍,就可能对当前线程的逻辑产生影响,导致逻辑错误。这一点的复现依赖于平台,偏强内存一致性模型的主要是x86,偏弱内存一致性有PowerPC、MIPS、ARM,RISC-V则两种都有支持。
不能复现是说,在x86等强序内存模型的平台上,即使显式地使用宽松的内存序,也不会有优化效果,因为CPU就不支持弱序。而像Arm等平台虽然能支持,但是和C++的内存模型仍存在一定的区别。
举一个CppReference的例子,
std::atomic<int> x{0}, y{0};
// 线程 1:
r1 = y.load(std::memory_order_relaxed); // A
x.store(r1, std::memory_order_relaxed); // B
// 线程 2:
r2 = x.load(std::memory_order_relaxed); // C
y.store(42, std::memory_order_relaxed); // D
由于A、B之间存在依赖关系,因此线程1运行时,无论选择什么样的内存顺序,都一定是先A后B。但是线程2中,由于C、D并没有依赖关系,而且此时选择了宽松的内存序(为了说明内存顺序问题)。此时可能的全局运行顺序可能有:ABCD、ACBD、ACDB、CABD、CADB、CDAB、ABDC、ADBC、ADCB、DACB、DCAB、DABC。
对于内存顺序不一致的情况。不同的CPU都提供了底层的指令来明确地插入内存屏障。但这种底层的方法显然需要进行进一步的抽象。因此C++需要有一种比较高层的抽象模型,对关键的代码指定其内存一致性模型,避免编译器和CPU指令重排造成错误的运行结果。原子变量的引入就是一种内存屏障,它保证了在原子变量写入的位置会执行一定程度的内存屏障,而具体的内存屏障水平则依赖于用户选择的内存顺序。
因此C++11开始引入内存顺序模型:std::memory_order。问题要从一致性开始说,为了尽量提高并发性能,对若干变量的修改,不应当强制要求立刻对所有线程可见,也不应当强制要求变量修改的可见性是顺序的,具体来说,可将这种并发种不同线程之间的数据一致性分类为四个等级:
- 线性一致性:完全线性化的修改,表现上就像是单核心单线程处理。
- 顺序一致性:读取数据一定能够读取到最近一次的修改,在最近一次修改之前的指令重排不做要求
- 因果一致性:只对有因果、依赖性的数据之间的同步做要求,而无关数据之间的修改不做要求
- 最终一致性:类似于分布式系统的最终一致,最终一定有某个时刻,修改将会对所有线程可见
一致性模型不仅给出了多线程之间的读写要求保证,更重要的是对一个线程内部的读写顺序要求。对于这四种一致性情况,C++使用了6种内存模型来表达,分别是
-
std::memory_order_relaxed:宽松顺序,在此情况下,不对内存顺序做任何要求。全局下不同线程之间看到的内存访问顺序都可能不一样。 -
std::memory_order_release、std::memory_order_consume:释放-消费顺序,已不再建议使用,很可能将被废弃或修改,而且也没有编译器真正实现了该层级。 -
std::memory_order_release、std::memory_order_acquire:释放-获取顺序- acquire:获得操作,在读取某原子对象时,当前线程的任何后面的读写操作都不允许重排到这个操作的前面去,并且其他线程在对同一个原子对象释放之前的所有内存写入都在当前线程可见
- release:释放操作,在写入某原子对象时,当前线程的任何前面的读写操作都不允许重排到这个操作的后面去,并且当前线程在该原子变量释放之前的所有内存写入都在对同一个原子对象进行获取的其他线程可见
注一:同步只发生在该原子变量语句本次同步所在的两个线程内。其他线程内观测到的内存访问顺序仍然可以是任意的。
注二:获得操作并不是阻塞的,也正如CppReference所说,标准要求,释放-获取内存序对内存修改的各种副作用的可见性的保障的一个前提是,当且仅当原子变量的获取操作,获取到了所期待的原子变量的释放操作的值,此时这一次同步才是真正有效。如下图示意
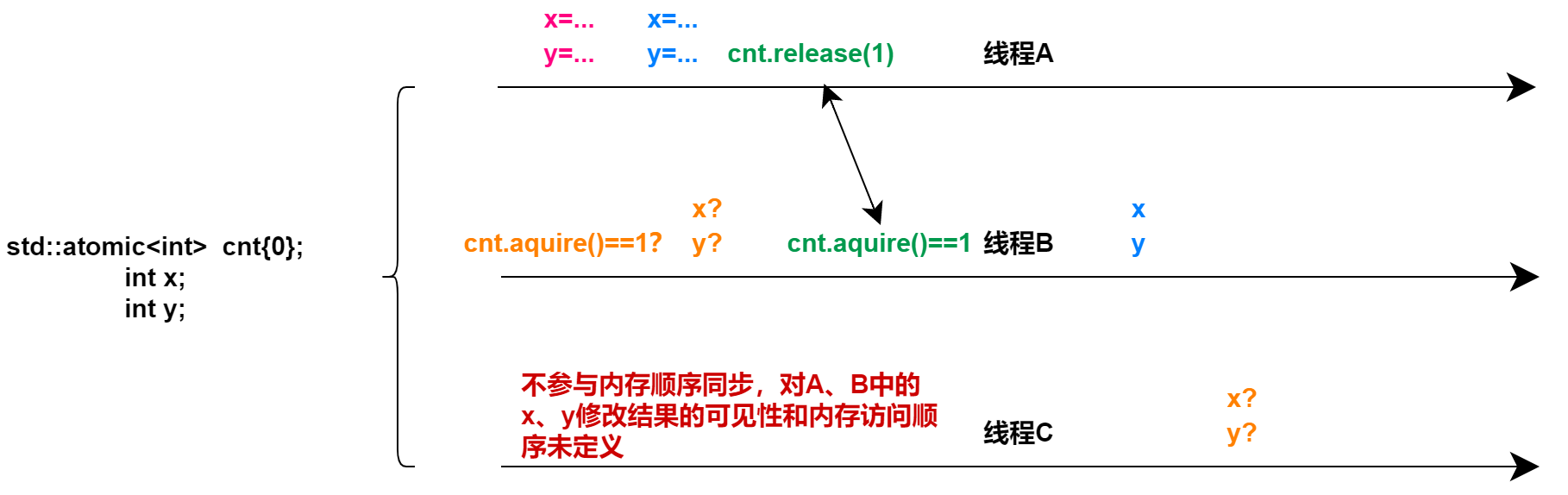
-
memory_order_acq_rel:释放-获取顺序。一个操作将同时具有获得语义和释放语义,即它前后的任何读写操作都不允许重排到另一侧,并且其他线程在对同一个原子对象释放之前的所有内存写入都在当前线程可见,当前线程的所有内存写入都在对同一个原子对象进行获取的其他线程可见。 -
std::memory_order_seq_cst:顺序一致顺序,在释放-获取顺序的基础上,还保证,所有的线程观察到的原子操作顺序一致。是C++的默认内存序。
至此,安全并发所需的三个特性:原子性、可见性、有序性。都能够得到不同程度的保证。
在实际应用中顺序一致性是最强的约束,也是C++默认的内存序。在实际编码中,肯定要优先保证正确性,而性能的优化则是一个很复杂的问题。并发算法更重要一些,并不是说无锁一定高效。在个别场景下,锁操作尤其是自旋锁可能会比无锁数据结构有更高的性能。
关于volatile,参考博文中有提到,volatile作为原本设计是用来标记为“易变”,提示编译器禁止对变量做任何读取优化,即每一次访问都必须从内存地址读取数据,除此之外没有保证内存顺序的要求。但实际使用中,在C++的不同编译器中出现了一定程度的滥用,比如实际上添加了内存同步指令。而且volatile和Java中的关键字也有一定程度上的类似,也加重了错误理解和滥用。实际上,无论是C++还是Java,都已经不在推荐使用volatile变量。具体的并发场景都应当使用原子变量、锁来完成同步。
电子书未完成项
模块
从C++20标准开始引入的源代码组织风格,参考CppReference模块。不同编译器都有一些自己的实现细节(比如对标准未定义行为的一些扩展,对标准中规定的错误进行一定的容忍),注意一定要检查编译器对其的支持情况,并尽量按照标准要求使用。
模块的术语不算很多,基本内容如下
- 模块声明:一个模块有且仅能有一个模块声明,如
export module A; - 导出声明和定义:
- 可以一个个导出,也可以在一个匿名、具名命名空间下一同导出,如
export namespace rex { void func1(); void func2(); } - 可以把导入模块顺便直接导出,例如
export import A;
- 可以一个个导出,也可以在一个匿名、具名命名空间下一同导出,如
- 导入模块或头文件:对自定义模块
import A,对于标准库import <iostream> - 全局模块片段:用于处理需要导入传统C++头文件的时候,在模块声明之前使用(即模块的首行),
module;- 全局模块片段到模块声明之间,只能使用传统预处理指令(主要是
#include),这是为了兼容传统C++头文件
- 全局模块片段到模块声明之间,只能使用传统预处理指令(主要是
- 私有模块片段:在私有模块片段后的内容,不会被导出(也不允许再导出),
module : private; - 模块分区:一个模块可以由多个分区组成,类似于包和子包,在声明时使用冒号分隔,例如
export module A:B;,代表A模块的B分区。
问题,如果不同的模块导出了相同名字的实体,并且在同一个文件中被导入,不一定会造成链接器报错,链接器会随机选择其中一个。因此请尽量使用命名空间进行区分。
模块的优点:
- 一个模块的所有文件将会进行一次编译,并生成一个编译结果,后续编译时引用该模块的源文件只需要直接使用该编译结果,而不需要再像以前一样,将头文件引入进来重新从词法分析开始处理。提高了编译速度。
- 更好的隔离性,不导出的内容对不同源文件、模块均不可见 模块现阶段(202401)的问题:
- 编译器支持不充分
- 模块编译结果的二进制分发问题,不同编译器厂商实现不同
- 链接复杂度进一步提升,包括项目文件的编写难度也进一步提升。
推荐是分成模块定义和实现文件,为了简单起见下面都放到一起了,一下是一个对模块特性的简单例子。
// MSVC 2022
// ====== MyModule.ixx ======
module;
#include <map>;
export module MyModule;
// 导入当前模块的B分区
export import :B;
import <iostream>;
// 宏仍然可用
#define DEBUG
export namespace MySpace {
void Func() {
std::cout<<"hello module!"<<std::endl;
}
#ifdef DEBUG
static int i = 0;
#endif // DEBUG
}
export class MyClass{
public:
void print() {
std::cout<<"hello MyClass"<<std::endl;
}
}
export template<typename T>
void Print(T t) {
std::cout << t << std::endl;
}
// ====== MyModuleB.ixx ======
export module MyModule:B;
export void HelloSub() {
std::cout<<"hello module B"<<std::endl;
}
// ====== main.cpp ======
// 顺便导入了:B
import MyModule;
int main(){
MySpace::Func();
}
协程
C++20引入协程,具体内容可参考CppReference协程,非常推荐:渡劫C++协程。在C++20标准下,协程的使用比较底层,并不适合直接使用,实际上官方的目的也是提供给库编写者使用,实际工程中需要自行封装或者用其他封装好的库。另外也有5篇很好的英文博客,地址Lewis Baker:Asymmetric Transfer,可以从原理上学习一下。
什么是协程,这一点在不同的语言中有着类似但是又不完全相同的定义。C++20引入的协程,要求是必须在函数体内部包含co_await、co_yield、co_return,其基本语法如下,
// 由表达式给出awaiter对象
// awaiter对象需要完成协程在暂停点前后的逻辑
co_await 表达式
// 等价于调用 co_await promise.yield_value(表达式)
co_yield 表达式
co_yield {初值列}
//
co_return 表达式
C++20的协程主要有几个类型,简单列举如下
- 承诺对象:承诺对象没有继承和实现上的限制,但是需要具有一些要求的接口,比如
initial_suspend、final_suspend、unhandled_exception等。同时承诺对象也负责协程句柄的创建。该对象交给协程内部操纵,通过该对象提交结果或异常。默认行为是在创建协程时构造(进入协程体函数之前),协程退出(正常/异常)时析构。在实际使用中,为了保证承诺对象的生命周期能够覆盖业务需要,协程退出的析构,很可能需要交给上层对象处理。因此需要在
final_suspend阶段选择挂起suspend_always,而不是继续执行导致销毁。 - 协程句柄(handle):由协程外部操纵,用于恢复协程执行(
resume)、切换协程所在线程、销毁协程帧(destroy)。协程句柄类型内当然也有承诺对象,因此外部也是可以从承诺对象获得数据的。 - 协程状态:内部对象,包含承诺对象、协程形参、暂停点信息、生命周期跨过当前暂停点的变量
- awaiter对象:该对象在进入暂停点时构造,离开暂停点恢复协程时析构。可以用来处理一些需要短暂跨过暂停点的数据。在awaiter对象中可以获得协程句柄。
对于这些类型的限制,需要从模板、概念中获得,比如查看
coroutine_traits。
了解了类型之后,还需要对一些概念进行解释
- 暂停点:由
co_await、co_yield触发,执行流到这里将会返回给调用者,协程保存状态。暂停点是协程最重要的概念。一定要明白协程的暂停返回,恢复执行的特点。而且协程在暂停点恢复执行时,不一定还在原来的线程,用户可以把它切换走。
下面转载一段实现序列生成器的协程用法
// 拷贝自https://github.com/bennyhuo/CppCoroutines/blob/master/02.sequence_2.cpp 添加注释
//
// Created by benny on 2022/1/31.
//
#define __cpp_lib_coroutine
#include <coroutine>
#include <exception>
#include <iostream>
#include <thread>
// 序列生成器
struct Generator {
class ExhaustedException : std::exception {};
struct promise_type {
int value;
bool is_ready = false;
std::suspend_always initial_suspend() { return {}; };
std::suspend_always final_suspend() noexcept { return {}; }
// 对 co_yield value; 的处理
std::suspend_always yield_value(int value) {
// 存储数据并标记为可用
this->value = value;
is_ready = true;
// 协程挂起
return {};
}
// 对未捕获异常的处理
void unhandled_exception() {
}
Generator get_return_object() {
// 结构化绑定
return Generator{std::coroutine_handle<promise_type>::from_promise(*this)};
}
// 对 co_return; 的处理
void return_void() {}
};
// 存储协程句柄
std::coroutine_handle<promise_type> handle;
// 序列生成器相当于协程的外部
bool has_next() {
if (handle.done()) {
return false;
}
// 未结束,且没有可用值,从暂停点唤醒
if (!handle.promise().is_ready) {
handle.resume();
}
// 从暂停点暂停后,再判断一次
if (handle.done()) {
return false;
} else {
return true;
}
}
// 获取序列下一个值
int next() {
if (has_next()) {
handle.promise().is_ready = false;
return handle.promise().value;
}
throw ExhaustedException();
}
// 要求必须显示调用
// 该构造函数实际由promise_type的get_return_type负责调用
explicit Generator(std::coroutine_handle<promise_type> handle) noexcept
: handle(handle) {}
// 允许移动
Generator(Generator &&generator) noexcept
: handle(std::exchange(generator.handle, {})) {}
// 禁止拷贝
Generator(Generator &) = delete;
Generator &operator=(Generator &) = delete;
// 保证二者生命周期的长度正确
~Generator() {
if (handle) handle.destroy();
}
};
// 自然数序列生成
Generator sequence() {
int i = 0;
while (i < 5) {
co_yield i++;
}
}
// 斐波那契数列序列生成
Generator fibonacci() {
co_yield 0;
co_yield 1;
int a = 0;
int b = 1;
while (true) {
co_yield a + b;
b = a + b;
a = b - a;
}
}
// 作为对比,普通的生成器
class Fibonacci {
public:
int next() {
if (a == -1) {
a = 0;
b = 1;
return 0;
}
int next = b;
b = a + b;
a = b - a;
return next;
}
private:
int a = -1;
int b = 0;
};
int main() {
auto generator = fibonacci();
auto fib = Fibonacci();
for (int i = 0; i < 10; ++i) {
if (generator.has_next()) {
std::cout << generator.next() << " " << fib.next() << std::endl;
} else {
break;
}
}
return 0;
}
概念和约束
概念和约束是C++20引入的用来规范、简化模板编程的,具体内容可参考CppReference约束与概念。在原有的代码中,模板匹配的最终失败往往会产生一系列难以阅读的编译错误。而且对于类型的判断需要用到大量模板元技巧,大大提高了使用门槛。概念和约束旨在结束这一混乱的场面。
概念是用来描述一种对模板形参的约束的,它的定义方式如下,
// 约束表达式是能够在编译器计算出true、false的
// 类似现有的模板元is_xxx<T>::value
template < 模板形参列表 >
concept 概念名 [可选属性] = 约束表达式;
约束则使用各类概念来对实际使用的模板形参进行限制,它的使用方式如下,
// 假定Incrementable Decrementable是两个概念
template<Incrementable T>
void f(T) requires Decrementable<T>;
// 或者
template<typename T>
requires Incrementable<T> && Decrementable<T>
void f(T);
概念和约束在使用过程中可以使用合取、析取,原子约束,也可以嵌套。其中关于原子约束、类型转换、约束歧义的要求可能比较难以理解,建议参考Concept详解以及个人理解。简而言之:
- requires后的表达式,必须具有显式的bool类型,即使能隐式转换也不行
- 原子约束是不包含任何合取和析取的约束,在编译器进行模板约束规范化时产生(就是拿着模板实参去约束表达式中替换形参并验证)。由于编译器需要根据不同的约束条件的强弱来作为模板展开时的选择参考,因此需要能够区分不同的约束的优先级。对于能够满足更严格约束的,用更严格约束的模板进行展开。这个选择过程中最大的问题在于需要消除歧义。例如CppReference的示例代码
template<class T> constexpr bool is_meowable = true; template<class T> constexpr bool is_cat = true; template<class T> concept Meowable = is_meowable<T>; template<class T> concept BadMeowableCat = is_meowable<T> && is_cat<T>; template<class T> concept GoodMeowableCat = Meowable<T> && is_cat<T>; template<Meowable T> void f1(T); // #1 template<BadMeowableCat T> void f1(T); // #2 template<Meowable T> void f2(T); // #3 template<GoodMeowableCat T> void f2(T); // #4 void g() { f1(0); // 错误,有歧义:无法比较两种约束的强弱 // BadMeowableCat 和 Meowable 中的原子约束is_meowable<T>虽然看起来一样 // 但是他们实际上是不同的原子约束(不在同一行),可以类比菱形继承 f2(0); // OK,调用 #4,它比 #3 具有更强的约束 // GoodMeowableCat 是从 Meowable 获得其 is_meowable<T>,他们是相等的 }原子约束相等的要求:在规范化(进行形参替换时)来自同一行、形参映射等价
concept还可以和requires进一步结合,产生requires表达式定义的概念,有四种不同种类的要求,可以描述更为复杂的逻辑,参考requires 表达式。
// 来自CppReference,添加注解
// 第一类,简单要求,判断语句是否满足语法
template<typename T>
concept Addable = requires (T a, T b)
{
a + b; // "需要表达式 a+b 可以被编译为有效的表达式"
};
// 第二类,类型要求,判断是否具备类成员,是否能满足类型运算
template<typename T>
concept C = requires
{
typename T::inner; // 需要嵌套成员名
typename S<T>; // 需要类模板特化
typename Ref<T>; // 需要别名模板替换
};
// 第三类,复合要求,用于判断一个表达式是否合法,语法比较特殊,用 {表达式} [noexcept可选] [-> ...返回类型要求];
// 判断表达式是否合法,是否noexcept,判断返回类型约束是否满足
template<typename T>
concept C2 = requires(T x)
{
// 表达式 *x 必须合法
// 并且 类型 T::inner 必须存在
// 并且 *x 的结果必须可以转换为 T::inner
{*x} -> std::convertible_to<typename T::inner>;
// 表达式 x + 1 必须合法
// 并且 std::same_as<decltype((x + 1)), int> 必须满足
// 即, (x + 1) 必须为 int 类型的纯右值
{x + 1} -> std::same_as<int>;
// 表达式 x * 1 必须合法
// 并且 它的结果必须可以转换为 T
{x * 1} -> std::convertible_to<T>;
};
// 第四类,嵌套要求,requires里requires
template<class T>
concept Semiregular = DefaultConstructible<T> &&
CopyConstructible<T> && Destructible<T> && CopyAssignable<T> &&
requires(T a, std::size_t n)
{
requires Same<T*, decltype(&a)>; // 嵌套:"Same<...> 被求值为真"
{ a.~T() } noexcept; // 复合:"a.~T()" 是不会抛出的合法表达式
requires Same<T*, decltype(new T)>; // 嵌套:"Same<...> 被求值为真"
requires Same<T*, decltype(new T[n])>; // 嵌套
{ delete new T }; // 复合
{ delete new T[n] }; // 复合
};
一些常见的约束可见概念库 (C++20)
其他杂项
文件系统
引入filesystem,具体特性在使用中查询标准。总的来说功能还是不够完全,现在可以获取文件权限、文件系统信息、文件/目录信息、移动拷贝、创建链接等。以下是一段简单代码示例
// 创建当前路径
const std::filesystem::path currentDir{"./"};
// 打开文件
{
std::ofstream f1{"./test.txt"};
}
// 遍历路径下所有目录项
for (auto const& dir_entry : std::filesystem::directory_iterator{ currentDir })
std::cout << dir_entry.path() << '\n';
// 获取当前路径
std::filesystem::path p = std::filesystem::current_path();
std::filesystem::create_directories(p / "from");
// 写入文件
{
std::ofstream{ p / "test.txt" }.put('a');
}
std::filesystem::create_directory(p / "to");
// 错误码
std::error_code ec;
// 重命名或移动
std::filesystem::rename(p / "test.txt", p / "from/test1.txt", ec); // OK
// 输出错误信息
std::cout << ec.message() << std::endl;
std::filesystem::rename(p / "from/test1.txt", p / "to/test2.txt",ec); // OK
// 输出错误信息
std::cout << ec.message() << std::endl;
异常
-
noexcept:
- 作为函数说明符(specifier):修饰的函数。用来告知编译器该函数不会抛出异常,此时编译器可以做一些优化。但在该函数有异常未处理企图向上传播时,会直接调用terminate来终止程序运行,无法被外层catch。从C++17开始,和返回值一样,是函数类型的一部分。注意不是函数签名的一部分,因此不能用来区分重载。
- 作为运算符,计算一个表达式是否可能抛出异常。
注意使用
throw来声明动态异常的语法已经在C++17之后废弃移除。应当统一使用noexcept替代。也就是从标记可能抛出哪些异常变成了,标记可能不抛出异常。
字面值
- C++11
- 原始字符串字面值(不做转义):包裹在
R"()"中,例如R"(your raw string)" - 自定义字面值:通过重载
operator ""实现,chrono中的时间长度表示就用了这个特性,5d、6min表示字面值5天、6分钟。
- 原始字符串字面值(不做转义):包裹在
正则表达式
C++11引入正则表达式,具有匹配、搜索、替换三种功能。其主要类型和作用如下:
std::regex:类模板,存储正则表达式,可以根据需要选择支持的正则表达式语法(ECMA、awk等)、匹配条件(如无视大小写等)std::sub_match:类模板,通过begin/end存储一个匹配的起始/结束。std::match_result:类模板,存储所有匹配结果,一般常用的是std::cmatch(const char *)、std::smatch(string)。其内存储了若干个sub_matches。regex_match():函数模板,只考虑完全匹配,即整个原数据刚好可以被正则表达式描述。regex_search():函数模板,考虑部分匹配,每一次匹配,可以获得匹配结果,匹配结果前缀,匹配结果的后缀。对后缀循环,就能计算出全部的匹配。regex_replace():函数模板,对匹配结果进行替换,替换所用的正则表达式语法也是可选的。regex_iterator:迭代正则表达式的匹配,可以通过原数据和正则表达式进行构造,可以通过迭代器遍历直接获得类似于regex_search的效果。通过迭代器可以获得match_result,无法获得子匹配的情况。regex_token_iterator:每个匹配结果和子匹配的迭代器,实现上内部可能持有regex_iterator,可以遍历匹配结果,以及每次匹配的某个指定子匹配。而且还可以通过调整构造函数参数,遍历由匹配片段分割的各个失配片段。
其基本使用如下例子所示
// 拷贝自cppreference
std::string s = "Some people, when confronted with a problem, think "
"\"I know, I'll use regular expressions.\" "
"Now they have two problems.";
// 使用ECMA正则语法,大小写不敏感
std::regex self_regex("REGULAR EXPRESSIONS",
std::regex_constants::ECMAScript | std::regex_constants::icase);
// 返回结果true/false表示是否存在部分匹配
if (std::regex_search(s, self_regex)) {
std::cout << "Text contains the phrase 'regular expressions'\n";
}
std::regex word_regex("(\\w+)");
// 匹配所有单词,构造匹配结果迭代器
auto words_begin =
std::sregex_iterator(s.begin(), s.end(), word_regex);
auto words_end = std::sregex_iterator();
std::cout << "Found "
<< std::distance(words_begin, words_end)
<< " words\n";
const int N = 6;
std::cout << "Words longer than " << N << " characters:\n";
for (std::sregex_iterator i = words_begin; i != words_end; ++i) {
// 匹配结果是smatch,也就是match_result<string>
std::smatch match = *i;
std::string match_str = match.str();
if (match_str.size() > N) {
std::cout << " " << match_str << '\n';
}
}
// 替换,$&代表将匹配的子结果整体保留,并前后添加方括号
std::regex long_word_regex("(\\w{7,})");
std::string new_s = std::regex_replace(s, long_word_regex, "[$&]");
std::cout << new_s << '\n';
目前来说,C++标准库中的正则表达式性能很可能还是很差(看平台和编译器),很多时候不如Python3的re,在实际使用场景下需要谨慎使用。