
面试总结:大全篇
目录
这篇笔记总结历次求职面试的经历,对笔试、面试题目进行总结,也会对非专业考察内容进行一定的梳理。
整体准备
- 心理:
- 放松心态
- 先思考整体,理清几个要点和思路,再谨慎答题
- 提前准备几个问考官的问题
- 行为面试:简短介绍自己(因为已经有简历了),项目经验介绍STAR(背景,完成的任务,做了哪些工作,自己的贡献),跳槽原因(和自己的发展目标不符,而目标公司符合)
- 技术面试:正确、鲁棒的高质量代码(鲁棒非常重要,一定要保证不能崩溃),软技能(沟通和学习能力)。 不要怕问问题,多问一些限制条件。 在不需要考虑栈上消耗的情况下,适当使用递归减少编程量。
- 准备几个问题:
- 公司的业务内容,具体的研发内容
- 岗位后续发展情况
- 团队氛围、工作时间
- 内部学习交流机会
专业性考察
C/C++
- 类型的最小大小?
- 空类型的sizeof是1(和编译器有关,但是必须在内存中占有一定空间)。添加普通构造和析构函数,仍是1。添加虚析构,占用计算机位长(e.g.8字节,原因:虚函数表,虚函数表指针)
- 对空类进行继承,如果派生类仍然没有数据成员或者虚函数表,大小仍然是1。但如果有虚函数表,或者对空类进行虚继承,那么vbptr、vfptr都是有的。
- 复制构造是否可以传值?
- 复制构造函数不允许是传值函数。传值会导致无限复制构造。
- 写一个赋值运算符函数?
- 4个要点:返回引用,参数是常量引用,释放旧空间,预先检查是否是自己。异常安全性问题(凡是new的时候都要考虑)。多线程安全问题。常见运算符重载
- sizeof的值?
- 数组:数组总长(字节数)
- 指针:计算机字长(字节数)
- 数组形参:退化为指针,仍然是计算机字长(字节数)
- char a[]=“hello”,sizeof(a)=?
- 6,字符串字面值结尾会自动添加"\0"
- char (*p)[5]和char* p[5]的区别?
- 根据括号优先原则,前者是一个数组指针,指向char[5],后者是一个指针数组
- 引用和指针什么时候不能互换?说一下二者区别
- 引用是一个别名,必须在定义处进行初始化。而指针是一个变量,可以有控制,可以被修改
- 引用只有一级,指针可以有多级
- 在const、sizeof、自增自减运算符等使用上均有不同的意义
- C++三种时钟的使用区别?
- steady_clock是启动时间,不可修改,high_resolution_clock是高精度时钟,system_clock是系统时间
- 什么是RAII?
- Resource Acquisition Is Initialization,也称为“资源获取就是初始化”
- 类中static成员的初始化时间
- 在程序启动时
- 什么是返回值优化RVO、NRVO?
- 是一项编译期优化技术,主要是为了消除函数返回值创建的临时对象。RVO是匿名变量优化,NRVO是具名局部变量优化
- 当满足优化条件的函数返回一个对象时,RVO和NRVO会消除掉临时变量的构造,以及赋值时产生的复制构造,直接在外部调用处进行一次构造
- 函数返回值不应当使用std::move,这样会导致无法进行RVO、NRVO优化,性能更低
- static_cast、dynamic_cast、const_cast、reinterpret_cast区别?
- 简单的答案是:分别主要用于静态强转(类似C的转换)、类型继承关系内的下行转换、移除const、指针转换
- 更完整一些的回答:
- static_cast是代替C风格的类型强转,支持对象、指针、引用的转换。通常用于有继承关系的类型之间,或者内置类型之间。是静态的转型,发生在编译期。因此对于具有虚函数RTTI信息的类型,使用static_cast意味着放弃了运行时的安全检验。但除此缺点之外。static_cast是能够进行父类子类之间(无论有没有虚函数)的上行、下行转换(会自动调整继承顺序内的指针位置,并恢复指针位置),而且速度更快。
- dynamic_cast是动态的转换,只对有多态属性(具备虚函数)的类型的引用和指针生效,发生在运行期。如果无法进行转换,对指针会返回nullptr,对引用会抛出异常。
- const_cast用于移除const属性(无论是引用、变量、指针),但是一定要清楚这个操作不会对数据的一致性产生错误的影响。而且对于字符串字面值,他的内容是存储在程序的只读内存区,对它的修改是未定义行为,不应该这样使用。
- reinterpret_cast是对内存的重新解释。同样的指针之间的转型,static_cast还会对其进行父类子类之间的起始位置的变化,而reinterpret_cast则完全不会,就是从当前地址重新解释。非常适合用于直接读取二进制数据,并重建对象。
- static_cast还承担了std::move的功能,实际上std::move的实现近似于
static_cast<remove_reference_t<T>&&>(value)。
- C/C++中一次malloc/new的完整流程?系统分配内存的系统调用是什么?
- 这个问题是比较复杂的,可以参考new和delete底层实现原理。2万字30张图带你领略glibc内存管理精髓。
- 用来分配内存的系统调用是brk、mmap、munmap。C库还提供了sbrk。
- make_shared和传递裸指针给shared_ptr的区别?
- make_shared更安全,而且由于make_shared是统一的一次内存分配,shared_ptr实际上是两次内存分配,使用make_shared,智能指针和实际对象会存储在相近的位置。
- 构造函数中能否调用虚函数?
- 可以调用虚函数,但是仍然会视为普通函数,类在构造构成中尚未建立虚函数表,不具备动态绑定能力,只会调用本类已具有的函数
- short i=65537;此时i的值是?
- 字面值默认是int,而且向下赋值的时候进行截断,所以i的值是1,而不是负数
- 以下代码
class A {public:virtual void a() {}}; class B {public:virtual void a() {}}; class C:public A,public B {public:virtual void a() {}}; C obj; A* pA = &obj; B* pB = &obj; C* pC = &obj; // 值是否相等 cout << pA << endl; cout << pB << endl; cout << pC << endl;- 多继承的派生类指针向基类转型时,会丢掉其虚表中,在继承时顺序位于当前基类之前的其他基类的虚表内容。因此pA和pC相等、而pB和pA、pC不相等。
- C++的多态有哪些
- 静态多态:模板、重载函数
- 动态多态:虚函数
- 为什么要引入右值引用:
- 主要是为了解决两件事情(完美转发、移动语义)
- 如何实现auto?
- 个人理解是编译期解析等号右侧、函数返回值的类型,并去除其中的const、&、volatile
- unique_ptr为什么比shared_ptr快?
- unique_ptr没有引用计数,在构造、析构、实用时都没有这方面的访存需求;shared_ptr存在一个原子引用计数需要维护
- map和unordered_map的底层实现?
- C++ STL中的无序容器都是在使用哈希表,并用开链法解决冲突
- map底层使用红黑树。
- 虚函数有哪些缺点
- 类型体积膨胀,潜在的无法跨平台(32位、64位寄存器问题),跨语言调用(在其他语言中没有对应的内存结构)的风险
- 参考虚函数、虚析构函数的缺点
- 链接时的重名符号优先级?
- 链接时的优先级,从目标文件,到静态链接库,再到动态链接库。相同层级的库内,以先后顺序为准。但是具体的细节很复杂。
- 链接主要完成两个任务,第一步是合并目标文件,第二步是符号解析与重定位。因此多个.o之间是严格控制符号重名的,不允许出现重复定义。
- 符号解析和重定位阶段,则有更大的灵活性。可以根据链接时的顺序,以及一些控制选项
--exclude-libs --no-as-needed --as-needed --allow-multiple-definition等,决定使用的具体符号。 - 参考动态链接库的符号重名问题
- volatile是做什么的,什么时候会用?
- volatile的设计目标是提示编译器,该变量可能在内存中随时改变。不应对其进行任何优化。这种设计最初主要是为了在信号处理(signal handler)、内存映射硬件(某个内存地址实际上是硬件映射提供的)、和setjmp/longjmp等场合使用。对该类型变量的操作,本身仍然是需要进行多次读写的。不是原子。
- 如果开启了CPU cache,则volatile变量有可能从缓存中读取。此时也涉及到MESI协议。
- 不是为了多线程中保持操作原子性的。如果要进行多线程同步,使用锁、原子变量。volatile只在特殊的内存需要时使用,避免编译器的优化。可以这么说,除非你明确知道你必须使用,否则volatile的使用都是错误的。
- 参考不要再误解C++ volatile了、多线程编程中什么情况下需要加 volatile?
- 如何查看cpu cache命中率?
- 通常需要使用一些专门的性能分析工具,如 perf 、 valgrind 、cachegrind 等。这些工具可以提供更详细的CPU cache相关的信息,包括缓存命中率、缓存行大小、缓存使用情况等。
- 例如
perf stat -e cache-misses,cache-references <your_program>
- C++有哪些内存区域?自由存储区和堆区的区别?
- 在C++中,内存区分为5个区,分别是堆、栈、自由存储区、全局/静态存储区、常量存储区。malloc在堆上分配的内存,使用free释放内存,而new所申请的内存则是在自由存储区上,使用delete来释放。基本上所有的C++编译器默认使用堆来实现自由存储,即缺省的全局运算符new和delete也会按照malloc和free的方式来被实现,这时藉由new运算符分配的对象,说它在堆上也对,说它在自由存储区上也正确。所以,new所申请的内存区域在C++中称为自由存储区,如果是通过malloc实现的,那么他也是在堆上的。
- 自由存储区是一个逻辑上的概念。
- final和override的应用场合?
- final是禁止继承该类或者覆盖该虚函数,写法
class MyFinal final {};。override是必须覆盖基类的匹配的虚函数。
- final是禁止继承该类或者覆盖该虚函数,写法
- C++的三法则、五法则是什么?什么时候需要写析构函数,什么时候需要写虚析构函数?
- 三法则和五法则说的是一件事情,如果显式定义了析构、复制构造、赋值运算、移动构造、移动赋值,这些中的任何一个,那么也应当编写其他4个。如果不进行编写,编译器也会自动生成,但可能不是我们要的结果。
- 举个例子,如果必须重新编写析构,说明有堆区的内存需要回收,那么此时编写其他函数,是避免出现浅拷贝,或者多份指针的重要手段。
- 换言之是零法则,如果你并不需要自己实现析构函数,那么就一个特殊函数都不要实现,让编译器帮你做完所有事情。
- 实际上,五法则的移动构造和移动赋值不实现也可以,但这意味着缺失了C++11之后非常重要的移动语义的性能优化。
- 不需要写虚析构的情况:这个基类没有派生类、或者基类和派生类都从来不在堆(heap)内存实例化、程序中没有指向派生类的基类指针或引用(没有使用多态)。如果全部不满足,就必须编写虚析构函数。当然,其他的情况并不是不需要写析构,这里是说不需要写虚析构。
- 为什么C++标准限制,不允许部分特化函数模板?
- 有没有看过无锁数据结构?
- boost中有三个LockFree数据结构,多写者多读者的queue、stack,以及单写单读的环状队列spec_queue。
- 参考1.84.0版本boost,第20章Boost.Lockfree
- 父类私有虚函数子类是否可以override?
- 可以。一个non-virtual 函数被定义为private时,它只能被该类的成员函数或友元函数所访问。但只要使用virtual修饰符则强调父类的成员函数可以在子类中被重写。编译器不检查虚函数的各类属性。被virtual修饰的成员函数,不论它们是private、protect或是public的,都会被统一的放置到虚函数表中。在子类中可以重新为这些重写的虚函数配置访问权限修饰符。
- C++标准中关于对齐的说明符?
- alignas说明符。指定类型或对象的对其要求。注意它可以针对类型整体(相当于设定类型对象的大小),数据成员分别设置。
struct alignof(cacheline_t) mycache_obj {}; 每个mycache_obj将对齐到缓存行(一个对象一行)
- alignas说明符。指定类型或对象的对其要求。注意它可以针对类型整体(相当于设定类型对象的大小),数据成员分别设置。
- 一个缓存行的大小?
- 根据CPU决定,一般是64字节。
- weak_ptr的原理?
- weak_ptr只能从shared_ptr或者其他weak_ptr构造。
- 根据CppReference的说明,一个典型的weak_ptr的实现,其内部存储了相关控制块、以及构造来源的shared_ptr的指针。当然如果是G++,也有weak_count和裸指针的实现。参考。
这里也就说明,其实shared_ptr的内容也没有单纯的一个原子变量引用计数那么简单。它里面也是有控制块指针的。
- 在实际的实现中(这取决于编译器和标准库的实现),shared_ptr 和 weak_ptr 通常会共享一个控制块,这个控制块包含、裸指针、强引用计数、弱引用计数
- 强引用清零时,将会删除对象,但是控制块会保留直到最后一个weak_ptr也被清除。
- 成员函数模板可以是虚函数吗?
- 不可以。在处理类型时,需要确定一个类是否存在虚表,以及表大小等。如果允许函数模板是虚函数。就需要直到所有的模板实例化情况,才能决定是否存在虚函数,以及虚函数的数量。这是不能接受的。
- 类模板可以有虚函数吗?
- 可以。但就像上一个问题说的,只能有虚函数,不能是函数模板做虚函数。
- 虚函数表都有哪些内容:
- 虚函数表的实现因编译器差异很大。
- 虚函数指针、类型信息RTTI指针、(可能)虚基类信息(用以调整this指针,访问虚基类部分)、thunk偏移(第二或后继的基类指针来调用派生类函数时需要修改指针的偏移值,而由于多态的真正对象必须在运行期确定,所以编译期不能确定具体的偏移量offset)
- 那些函数不能是虚函数? inline, static, constructor三种函数都不能带有virtual关键字。这三者和虚函数的原理都有冲突。
- inline都有哪些作用?
- 解决链接时多个定义的问题,inline之后,只要定义都相同,是允许多个定义的
- 建议编译器对函数做内联优化
- 内联变量(C++17),允许变量在头文件中定义,且不违反ODR(One-Defination Rule),尤其适合静态成员变量
- 模板和头文件,函数模板自带内联语义,不需要被显式的定义。如果是类模板成员函数,也建议直接在类内定义,而不是跑到类外(再使用inline)。模板实例化和inline是两个过程,如果你的函数需要做成inline的就把它声明为inline(也可以隐式地),否则仍然把它声明为正常的函数。
- 另外注意:C++要求对一般的内置函数要用关键字inline声明,但对类内直接定义的成员函数,可以省略inline,因为这些成员函数已经被隐含地指定为内置函数了。应该注意的是:如果成员函数不在类体内定义,而在类体外定义,系统并不是把它默认为内置函数,调用这些成员函数的过程和调用一般函数的过程是相同的。如果想将这些成员函数指定为内置函数,则应该加inline关键字。
- 更好理解的方式:inline目前的作用是把强符号变为弱符号。如果需要强制inline,需要使用编译器提供的能力。根据平台,可能是__forceinline或attribute(__inline)。
- 如果头文件定义了函数,源文件不实现,会在哪个环节报错?如果构建的是静态库,会报错吗,为什么?如果未调用过,会报错吗?
- 会在编译器链接(linking)阶段报出未解析的外部符号(unresolved external symbol)错误,因为编译器在编译过程中会为每个未实现的函数调用生成一个外部链接请求。
- 如果你在创建一个静态库(.lib或.a文件)时忽略了一个函数的定义,这个错误可能不会立即在创建静态库的过程中报出。这是因为静态库的构建只涉及编译各个源文件和将编译产生的目标文件(.obj或.o文件)打包到库中,并不进行链接。
- 如果头文件和源文件是应用程序的一部分,或者你正在构建一个动态链接库(.dll或.so文件),未定义的函数将在链接阶段导致错误。链接器将尝试解析所有外部符号引用,并给出错误信息提示无法解析的符号。
- 如果未进行过调用,则链接器一般不会对其进行处理,因为它也没有出现在需要解析的符号表中。
- mutex的实现原理?
- 线程阻塞、同步。并进行上下文切换,需要依赖于操作系统提供的同步原语(比如内核调用)。相比之下原子变量一般不需要陷入内核态。
- atomic的实现原理?真的没锁吗?
- 行为取决于编译器、平台和硬件。也取决于它需要支持的类型。如果硬件允许对某种类型大小的数据进行原子操作,可以直接使用这些CAS指令,此时就是无锁的。这个比较通常是需要逐bit比较的。如果不能支持特定的大小或类型,那么会退化到使用锁(比如使用某种形式的自旋锁)
- C++还有哪些锁类型,都有什么特点?
- std::mutex: 提供最基础的互斥锁功能,一次只允许一个线程持有锁。同一个线程重复上锁会抛出异常
- std::recursive_mutex:允许同一个线程多次获取同一锁(递归锁),内部通过计数来实现,以记录同一线程获取锁的次数,以保持内部状态的一致性。
- std::timed_mutex:除了基本的互斥功能外,还提供了尝试锁定一段时间的功能,如果在指定时间内没有获取到锁,线程可以决定做其他事情。
- std::recursive_timed_mutex:结合了recursive_mutex和timed_mutex的特点,允许一个线程多次获取同一个锁,并且可以指定尝试获取锁的时间。
- std::shared_timed_mutex:在C++14中引入,允许多个读取者线程同时持有锁(共享锁),但写入者线程需要独占访问,配合std::shared_lock使用使得读写锁更为便捷。
- 静态链接和动态链接的区别?
- 静态链接是指在程序编译时将所有用到的库(库代码)链接成一个单独的可执行文件的过程。静态链接库通常以.lib(Windows)或.a(Unix/Linux)为文件扩展名。它包含了全部的所需代码,不需要动态加载。代价就是文件更大,而且如果修改需要重新编译。
- 动态链接是指编译程序时只进行符号的解析和地址的重定位,具体的库函数代码在程序运行时才从共享库中载入内存。动态链接库通常以.dll(Windows)或.so(Unix/Linux)为文件扩展名。需要动态载入,且有版本兼容性的问题。但是减少了文件大小,而且可以共享库,随时替换。
- 如何在C/C++中手动获取调用堆栈?
- 这种需求主要是为了调试程序,在一些场合下由于堆栈破坏、core目录权限、core文件大小,无法正确生成core文件。参考coredump 堆栈被写坏问题定位、如何处理栈被破坏导致的crash、在C/C++程序中打印当前函数调用栈、。注意由于操作系统、CPU平台不同,想要触发一个堆栈覆盖写的问题,可能需要不同的代码(比如x86上linux的栈空间整体是从高到低分配,在每一个数组内部则按下标又是从低到高)。
- 一个比较基础的方案,参考C++程序崩溃时获取函数调用栈信息。编写固定的系统信号回调,并在内部打印栈帧、寄存器信息。主要函数有
backtrace、backtrace_symbols、backtrace_symbols_fd。目前C/C++尚未完成对此类函数的统一标准。
- 写出尽可能多的,令程序崩溃的一行代码?
// 受制于平台和编译器,以下行为并不全都一定会引发异常 (*(int*)0 = 0); // 非法地址解引用 int main(){main();} // 无限递归耗尽空间 int a = 1 / 0; // 除零异常 abort(); // 异常退出 assert(false) // 断言 int arr[1]; int b = arr[10000000]; // 越界访问数组 *(int*)(0x12345678) = 0; float c = 1.0f / 0.0f; ((void(*)())0)(); // 调用非法地址 throw std::runtime_error("Crash"); // 抛出异常
Java-Spring
- 压测如何分析性能?
- 使用系统分析器,例如linux的perf,可以分析系统性能
- JVM分析器,例如hprof,jprofiler,也可以用jdk自带的工具,如jstack、jmap、jstat、jcmd,以及JMX、JFR等工具。
- Java线程和操作系统线程之间的对应关系
- 曾经有绿色线程和本地线程的区别,但目前都是本地线程,也就是Java线程和操作系统线程是1:1的。
- 参考深入聊聊java线程模型实现?
- CMS和G1的区别
- 参考JVM收集器CMS与G1区别和优缺点分析、这三大特性让G1取代了CMS
- G1(标记整理)相比于CMS(标记清除),使用了分Region的思想,并不再将分代内存连续分配(可以eden、survivor、old乱序相邻),衡量回收内存效益最大的Region,以在回收时达到控制GC停顿时间的目的(目标是可预测的停顿时间,相比之下CMS扫描整个老年代)
- CMS会产生内存碎片,而G1不会
- CMS只针对老年代、G1对新生代和老年代都有效
- CMS对CPU敏感
- 过滤器、拦截器、AOP的区别和使用场景
- Tomcat容器提供的处理顺序是:filter、servlet、interceptor、controller
- 过滤器的实现基于回调函数,过滤器是JavaEE标准、也是Servlet容器规范的一部分,由servlet进行回调。
- 拦截器可以拦截IOC容器中的各个bean,拦截器是Spring提供并管理的,是通过反射实现的。拦截器依赖于SpringMVC的,需要有mvc的依赖。
- 过滤器和拦截器的区别简单来说:生效时间不同、过滤器可以修改request、过滤器只能在servlet中实现、拦截器可以在任何spring支持的环境中。
- 三者在拦截能力上的区别
- 过滤器并没有定义业务用于执行逻辑前、后等,仅仅是请求到达就执行。
- 拦截器有三个方法,相对于过滤器更加细致,有被拦截逻辑执行前、后等。
- AOP针对具体的代码,能够实现更加复杂的业务逻辑。
- 更多细节参考博客园
- @Autowired的替换品
- 使用@Resource替换,或者使用@RequiredArgsConstructor构造器方式注入。不推荐Autowired的主要原因是属性注入会有一些问题。首先是在构造器中注入未完成,无法使用;其次是添加注解太简单会导致某个类异常庞大,说明设计上有所欠缺;属性注解会造成类不能通过反射创建,必须强依赖容器,在spring容器之外无法使用。
- 推荐用法就是强制依赖就用构造器方式,可选、可变的依赖就用setter注入
- 参考@Autowired依赖注入为啥不推荐了
- JVM大对象分配位置,如果survivor区不够了怎么办,什么是分配担保
- 受GC算法影响,在Parallel New和Serial中有参数-XX:PretenureSizeThreshold,超过的大对象将直接分配在老年代
- survivor区不够了由老年代进行分配担保,即将超出的存活对象,移动到老年代
- 分配担保是MinorGC和FullGC进行取舍时的一个概念,如果GC前发现新生代的已用内存总数大于老年代剩余连续空闲内存,那么这一次GC是有风险的,如果存在需要分配担保的情况,将数据移动到老年代,老年代也可能发生空间不足。因此在这种情况下,可能会使用FullGC来确保空间足够。
- Springboot和Spring,和Java传统web开发有什么区别?
- Spring Boot中的Starter到底是什么。
- starter是基于 Spring 已有功能来实现的。首先它提供了一个自动化配置类,一般命名为 XXXAutoConfiguration。
- 在这个配置类中通过条件注解来决定一个配置是否生效(条件注解就是Spring 中原本就有的),然后它还会提供一系列的默认配置,也允许开发者根据实际情况自定义相关配置,然后通过类型安全的属性注入将这些配置属性注入进来,新注入的属性会代替掉默认属性。正因为如此,很多第三方框架,我们只需要引入依赖就可以直接使用了。
- 什么是 JavaConfig?
- Spring JavaConfig 是 Spring 社区的产品,它提供了配置 Spring IoC 容器的纯 Java 方法。因此有助于避免使用 XML 配置。JavaConfig在SpringBoot中被广泛使用。
- tomcat、servlet、spring之间的关系?
- tomcat是http服务器,提供最基础的监听端口,建立连接,获取请求的功能。具体的业务,需要由满足接口定义的servlet实现。servlet设计上是单实例多线程的。通过web.xml的定义和tomcat进行配合。
- springboot内直接集成了tomcat、以及DispatcherServlet。
- 参考Servlet/Tomcat/ Spring 之间的关系
- ConcurrentHashMap的原理,以及1.7到1.8的主要修改
- 首先,还有一个线程安全的类,是HashTable,它使用synchronized来锁住整张Hash表来实现线程安全,即每次锁住整张表让线程独占,相当于所有线程进行读写时都去竞争一把锁,导致效率非常低下。
- ConcurrentHashMap使用了锁分段技术。它使用了多个锁来控制对hash表的不同部分进行的修改。在1.7中,它做了二次Hash,使用段(Segment)来表示哈希表的不同分段,在每个分段内有一系列HashEntry,每个Entry内是一系列的KeyValue。对于读操作,可以不用上锁,而写操作,只需要锁住对应的段就可以,其他段仍然可以继续读写。
- 1.8进一步优化了锁的粒度,达到了HashEntry级别。并且采用了CAS无锁算法。并使用了红黑树来优化HashEntry内的链表,提高查询效率。
- ConcurrentHashMap也不是银弹,它二次hash本身就有一定的性能浪费,如果不是必要,使用本地的HashMap。而且严格来说读取操作不能保证反映最近的更新。如果A进程在putAll更新大量数据,B进程是可能在中间时刻读取到更新了一半的数据的。
- 参考一文读懂Java ConcurrentHashMap原理与实现
- 说一下ThreadPool的原理,如果core/max/blockingqueue各是5,10,10,输入50个长耗时的任务,问表现
- 通过池化技术,合理的分配线程执行任务。避免了处理任务时创建销毁线程开销的代价,另一方面避免了线程数量膨胀导致的过分调度问题,保证了对内核的充分利用。
- 继承结构:ThreadPoolExecutor、AbstractExecutorService、ExecutorService、Executor
- 核心原理:ThreadPoolExecutor实现的顶层接口是Executor,顶层接口Executor提供了一种思想:将任务提交和任务执行进行解耦。用户无需关注如何创建线程,如何调度线程来执行任务,用户只需提供Runnable对象,将任务的运行逻辑提交到执行器(Executor)中,由Executor框架完成线程的调配和任务的执行部分。ExecutorService接口增加了一些能力:(1)扩充执行任务的能力,补充可以为一个或一批异步任务生成Future的方法;(2)提供了管控线程池的方法,比如停止线程池的运行。AbstractExecutorService则是上层的抽象类,将执行任务的流程串联了起来,保证下层的实现只需关注一个执行任务的方法即可。最下层的实现类ThreadPoolExecutor实现最复杂的运行部分,ThreadPoolExecutor将会一方面维护自身的生命周期,另一方面同时管理线程和任务,使两者良好的结合从而执行并行任务。
- ThreadPoolExecutor共有5种状态:RUNNING(接受提交)、SHUTDOWN(不接受提交但可以处理剩余的)、STOP(不接受也不处理)、TIDYING(已经完成所有工作线程的关停)、TERMINATED
- 提交时根据当前的workerCount和core、max配置,有多种阶段。小于core时直接创建线程并执行,大于core小于max时进入阻塞队列(不满),大于core小于max但阻塞队列已满则创建新线程,等于max且队列已满则不再接收
- 通过一个锁机制,判断工作线程是否真的在工作,可以对线程进行安全回收
- 参考Java线程池实现原理及其在美团业务中的实践
- 什么是偏向锁(这里较为复杂,建议看一下视频)
- 这个问题就是再问,无锁(CAS) VS 偏向锁 VS 轻量级锁 VS 重量级锁。这四种锁是指锁的状态,专门针对synchronized的。synchronized是悲观锁,该锁就是存在Java对象头里的。
- Java对象头中存储了Mark Word字段。从无所到重量级锁,其标志分别是01,01,00,10。另外每一个Java对象就有一把看不见的锁,称为内部锁或者Monitor锁。线程也有一个私有的Monitor数据结构,每一个线程都有一个可用monitor record列表,同时还有一个全局的可用列表。每一个被锁住的对象都会和一个monitor关联,同时monitor中有一个Owner字段存放拥有该锁的线程的唯一标识,表示该锁被这个线程占用。
- 无锁没有对资源进行锁定,所有的线程都能访问并修改同一个资源,但同时只有一个线程能修改成功。
- 偏向锁,是当一个线程访问同步代码块并获取锁时,会在Mark Word里存储锁偏向的线程ID。在线程进入和退出同步块时不再通过CAS操作来加锁和解锁,而是检测Mark Word里是否存储着指向当前线程的偏向锁。引入偏向锁是为了在无多线程竞争的情况下尽量减少不必要的轻量级锁执行路径,因为轻量级锁的获取及释放依赖多次CAS原子指令,而偏向锁只需要在置换ThreadID的时候依赖一次CAS原子指令即可。注意偏向锁已经在Java15以上被废弃。
- 轻量级锁,是指当锁是偏向锁的时候,被另外的线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,从而提高性能。
- 升级为重量级锁时,锁标志的状态值变为“10”,此时Mark Word中存储的是指向重量级锁的指针,此时等待锁的线程都会进入阻塞状态。由于这一步需要进行系统调用,产生Mutex lock,因此存在内核和用户态切换,性能差。
- 参考不可不说的Java“锁”事、Java面试Synchronized锁升级的原理
- Java都有哪些常见的锁
- 内置锁(synchronized)、可重入锁(ReentrantLock)、读写锁(ReadWriteLock)、乐观读锁(StampedLock)
- JMeter有哪些模式
- 主要分为:GUI模式(适合小型的压力测试环境)、命令行模式(适合压力更大的场景,但压力机仍然位于当前主机)、远程模式(由本地客户端和远程压力机组成,压力机可以水平扩展)
- 参考Jmeter远程模式原理及环境搭建
- CMS和G1有哪些区别?
- CMS只针对老年代,使用标记-清除算法(因为会产生内存碎片,所以针对新生代使用CMS是不可接受的),并发收集(但也因为并发收集和清理会导致CPU敏感,影响工作线程),停顿比之前的GC低了。
- G1可以更好的利用多CPU、打破了传统分代收集,分为若干小Region,通过选择回收价值最高的Region进行回收,靠多次回收完成清理,垃圾扫描和收集时间更可控,基于标记整理,不会产生内存碎片。
- 参考弄明白CMS和G1,就靠这一篇了
网络
- IP协议的主要功能?
- 定义了在TCP/IP 互联网上数据传送的基本单元。为克服数据链路层最大帧长的限制,提供数据分段和重组的功能。
- 提供用于寻址的标志,寻找网络中每个主机,完成路由选择功能。
- 包含了不可靠分组传送的规则,指明分组处理、差错信息发生以及分组丢弃等规则
- MTU是什么?
- 最大传输单元MTU,是指网络能够传输的最大数据包大小,以字节为单位。如果MTU超过了接收端所能够承受的最大值,或者是超过了发送路径上途经的某台设备所能够承受的最大值,就会造成报文分片甚至丢弃,加重网络传输的负担。如果太小,那实际传送的数据量就会过小,影响传输效率。早期的以太网使用共享链路的工作方式,为了保证CSMA/CD(载波多路复用/冲突检测)机制,所以规定了以太帧长度最小为64字节,最大为1518字节。最小64字节是为了保证最极端的冲突能被检测到,64字节是能被检测到的最小值;最大不超过1518字节是为了防止过长的帧传输时间过长而占用共享链路太长时间导致其他业务阻塞。所以规定以太网帧大小为64~1518字节,虽然技术不断发展,但协议一直没有更改。
- 这个最小长度和网速以及网线长度有关,以太网的端到端往返时延 2τ 称为争用期,或 碰撞窗口。经过争用期这段时间还没有检测到碰撞,才能肯定这次发送不会发生碰撞。以太网取51.2μs为争用期的长度对于10 Mb/s以太网,在争用期内可发送512 bit,即64字节。显然,网速越高,争用期可以发送的数据越多。
- 参考什么是MTU 、载波监听多点接入/碰撞检测
- 什么是流量控制和拥塞避免?
- 流量控制是用发送、接收窗口进行控制,目的是防止接收方处理数据不及时造成丢包
- 拥塞避免是TCP发送包时,对网络环境的一种考虑,保持分组以合理的速度进入网络,避免网络中的某一段出现拥塞而丢失报文
- TCP的可靠性是如何保证的?
- 连接时的三次握手、超时重发、流量控制和接收发送滑动窗口、拥塞控制(慢启动、拥塞避免、快重传和快恢复)
- 如何优化TCP连接的大量TIME_WAIT状态?
- 优化内核参数:允许TIME_WAIT状态套接字直接用于新TCP连接,快速回收TIME_WAIT套接字,缩短MSL超时时间,减少允许处于TIME_WAIT的套接字数量、增加可用端口范围
- 在系统的各个部分连接中,尽量使用长连接(客户端-网关-后端)
- 负载均衡的底层实现?
- 在数据链路层:通过伪MAC地址接收,再分发给实际MAC
- 在网络层:通过伪IP接收,再分发给实际IP
- 在传输层:伪(IP+端口),再分发
- 在业务层:使用虚拟URL,再分发给不通的业务主机
- 什么是I/O多路复用?有哪些?应用场景
- IO 多路复用是一种同步IO模型,实现一个线程可以监视多个文件句柄。一旦某个文件句柄就绪,就能够通知应用程序进行相应的读写操作。没有文件句柄就绪就会阻塞应用程序,交出CPU。
- 使用I/O多路复用是为了解决BIO(同步阻塞)、NIO(这里指轮询查询的方式,同步非阻塞)的问题。
- select:需要轮询提交的所有I/O事件表中是否有可用的。poll和select没有本质区别,只是没有了最大表的限制(和文件一致为65535),采用链表实现。这两都是轮询。他们每一次需要将希望监听的I/O事件,从用户空间提交到内核空间。内核轮询所有的I/O事件,返回可用的。从这一点上来看是O(n)的。
- epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎样的I/O事件通知我们。所以我们说epoll实际上是**事件驱动(每个事件关联上fd)**的,此时我们对这些流的操作都是有意义的。epoll也只在每一次最初提交的时候,才会将等待的I/O事件,从用户空间拷贝到内核空间。每次回调也是直接发起(复杂度降低到了O(1))。
- 目前Redis是使用epoll的I/O多路复用,Netty根据使用场景(受JDK和系统限制),分别有select/poll/epoll的实现。
- 参考彻底理解IO多路复用实现机制
- Reactor和Proactor的区别?
- 和I/O多路复用相关。在 Reactor 模式中,Reactor 等待某个事件或者可应用或者操作的状态发生(比如文件描述符可读写,或者是 Socket 可读写)。然后把这个事件传给事先注册的 Handler(事件处理函数或者回调函数),由后者来做实际的读写操作。其中的读写操作都需要应用程序同步操作,所以 Reactor 是非阻塞同步网络模型。如果把 I/O 操作改为异步,即交给操作系统来完成就能进一步提升性能,这就是异步网络模型 Proactor。
- 参考Linux高性能IO网络模型对比分析:Reactor vs Proactor
- 除了三次握手和四次挥手,TCP还有别的连接和断开方式吗?
- 在连接和断开时,如果双方都在很短事件内同时发起连接、发起断开连接,则有同时打开和同时关闭,两种特殊的连接和断开模式。此时是四次握手,但仍是四次挥手。状态机也都是镜像的分别是SYNC_SENT、SYNC_RECV、ESTABLISHED。和FIN_WAIT_1、CLOSING、TIME_WAIT。
- 参考TCP状态转换图总结、计算机网络:TCP同时打开和同时关闭
- TCP和UDP可以监听同一个端口吗?
- 可以,TCP和UDP在多种情况下,都可以使用同一端口。首先只有TCP存在监听,而UDP则是recvfrom,在两者的绑定过程中,TCP模块和UDP模块是分开的,因此虽然是同一端口,但实际会交给不同的模块进行处理,并不会出现冲突。而TCP绑定端口,则也需要考虑所用的网络IP(也就是0.0.0.0,192.168.1.10这种),如果IP不一致,在模块眼中,实际上仍然是不同的端口(考虑最终是通过四元组来确定一个TCP连接的)。
- 而对于TCP来说,主要的端口冲突,除了确实和正在运行的端口冲突以外,也有可能是申请了一个处在TIME_WAIT状态的端口,此时可以通过配置 net.ipv4.tcp_tw_reuse 这个内核参数。允许直接打开该端口并使用。
- 参考:字节一面:TCP 和 UDP 可以使用同一个端口吗?
分布式
- 什么是CAP、BASE
- CAP定理指一个分布式系统,最多只能同事满足C(Consistency)一致性、A(Availability)可用性、P(Partition Tolerance)分区容错性中的两个。对于大多数系统来说,P是必须保证的(网络分区发生时,系统能继续运行),所以需要在C和A之间取舍。例如zk和etcd侧重CP,eureka是去中心化的对等节点所以侧重AP
- BASE理论是CAP的一个发展,对C和A进行权衡的结果,Basically Availability基本可用,Soft State软状态(允许数据存在中间状态,但不影响可用性),Eventually Consistent最终一致性(经过一段时间一定能达到一致)。
- 对最终一致性的保证通常有三种方式:读时修复(读取时发现数据不一致就进行修复)、写时修复(写失败定时重写)、异步修复(常用,定时检测副本一致性)
- 说说服务发现和负载均衡机制的实现?
- 参考技术文章摘抄-服务治理
- 在微服务架构中的负载均衡是指服务消费者在发起 RPC 调用之前,需要感知有多少服务端节点可用,然后从中选取一个进行调用。有多种负载均衡策略,Round-Robin 轮询、Weighted Round-Robin 权重轮询、Least Connections 最少连接数、Consistent Hash 一致性 Hash 等。这里以一致性Hash为例。服务器可以选择 IP + Port 进行 Hash。所谓的一致哈希,就是使用了更大的模(比如2^32),这样所有的节点(消费者和生产者)都位于一个环上。每个消费者寻找在环上的下一个服务器即可。同时为了更好的均衡各个服务器之间的连接数量,还会在哈希环上添加若干虚拟服务节点(比如一个物理节点扩充3个虚拟节点),来避免不均衡。
不使用普通哈希是因为,普通的哈希,如果模数就是节点数的话,一旦服务器节点数量变化,连接全部会断,最糟糕的情况下会发生数据迁移。降低了性能
- 分布式事务有哪些实现方式?
- 2PC:两阶段事务,事务准备和事务提交,事务协调者询问所有资源提供者,能否进行某个事务,得到肯定后开始向所有资源提供者发起提交。问题是在准备期长时间锁定资源、协调者单点故障可能导致事务永久上锁、第二阶段可能出现某次rollback/commit失败导致数据不一致。
- 3PC:三阶段事务。协调者和参与者引入超时机制。并将准备阶段进一步细分为,canCommit(是否具备执行事务)和preCommit阶段。但是仍然有第三阶段rollback部分节点未收到的数据不一致问题。
- XA:XA 协议是由 X/Open 组织提出的基于2PC、3PC模式的分布式事务处理规范。规范了术语,AP应用程序、TM事务管理器、RM资源管理器、CRM通信资源管理器如中间件。
- TCC:Try-Confirm-Cancel,TCC是基于BASE理论。XA的两阶段提交是基于资源层面的,而 TCC 也是一种两阶段提交,但它是基于应用层面的。业务服务需要提供try、confirm、cancel,业务侵入性强。而且confirm、cancel必须做幂等接口,以防止重复操作问题。由于是业务实现,每个Try都是业务独立完成本地事务,因此不会对资源一直加锁。
- 参考分布式事务笔记(XA,TCC,Saga)
- 秒杀系统中的超卖问题如何解决
- 基本的思路就是通过层层限流(要尽量保证公平,根据用户信息做风控),保证最后只有少量请求能真正拿到令牌,进入到尝试读写库的环境
- 将库存数据前移,分散到多个redis中,下单时预减库存,并配合延迟消息队列,判断是否支付以决定是否需要恢复库存。使用redis提供的锁(set指令),对redis内的库存数据进行扣减,扣减成功的才能提交订单到MySQL和消息队列中。并由下游的支付等模块继续处理。
- 参考电商系统如何防止超卖? - 苏三说技术的回答 - 知乎、【双十一】我教女票做秒杀
- 分布式缓存一致性的实现方案有哪些
- 思考一个复杂场景,主从DB、主从Redis,此时根据对数据一致性的要求,可用使用同步和异步的方式。如果要求强同步,则需要在业务中用事务完成对数据库、缓存的双写。不要求强同步,则可以在业务本地开启异步任务,刷新缓存,或者由MySQL的binlog负责异步更新缓存。
- 术语上是:CacheAside(先写库,再删除缓存)、Read/Write Through读穿写穿(程序只和缓存代理通信,由缓存代理自行负责去数据库更新,很少用因为Redis等并不支持)、WriteBack(更少用,这里是只修改缓存为脏,由其他组件保证将数据异步写入到磁盘)
- 参考https://blog.csdn.net/software444/article/details/106050496
数据库
- 聚簇索引优势在哪儿?辅助索引为什么使用主键作为值域?
- 由于行数据和叶子节点存储在一起,这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键Id来组织数据,获得数据更快。
- 辅助索引使用主键作为"指针" 而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时辅助索引的维护工作,使用聚簇索引就可以保证不管这个主键B+树的节点如何变化,辅助索引树都不受影响。
- NULL对索引的影响?
- 以MySQL5.7版本InnoDB引擎为例,索引内可以有NULL值,此时如果使用is NULL,索引仍然可以生效,甚至在联合索引内也是可以的。但是如果使用is NOT NULL,则索引失效。
- 对于部分数据类型来说,允许可NULL甚至比不允许要耗费更多的存储空间,因此除非有必要,所有列都应当禁止NULL,并设置默认值。
- 普通索引和主键索引的区别?
- 普通索引没有任何限制、值可以为空、值也可能重复
- 主键索引必须不空、不重复,而且一个表只能有一个主键索引
- 缓存雪崩?缓存击穿?缓存穿透?
- 雪崩是很多key同时过期,造成海量查询到数据库。可以通过分散过期时间、热点数据不过期、设置二级缓存的方式
- 击穿是单一key过期,但此key又有大量查询。热点数据不过期,定时更新,二级缓存,引入JVM本地缓存。
- 穿透是大量非法数据查询抵达数据库,使用布隆过滤器比较好
保护DB的所有场景,都可以使用熔断、限流、降级。
- 热key和大key的优化?
- redis有乱序问题吗?为什么不用多线程?
- 有乱序问题,可以用事务。redis是内存数据库,内存的处理速度已经很快,而且每个命令不仅仅是读写某个key的对象,还有很多全局数据(比如:服务器状态、统计、内存分配等等),这些全局数据会让线程竞争,而且多线程也有额外的线程切换成本,使用多线程反而降低了效率。Redis虽然没有使用多线程,但是使用了IO多路复用技术,在处理请求方面速度还是很快的。
- redis有那些部署模式,有什么区别?
- 主从模式(需要主从同步),一般读写分离
- 哨兵模式,在主从模式中,主节点的健康情况,需要引入额外的设计来确保,哨兵模式下增加了一个哨兵集群,用于检测主节点健康,并负责主节点选举。哨兵节点也会主动发送info魔灵来获取最新的Redis集群拓扑结构。
- 集群模式:官方实现的高可用方案,Redis Cluster + Master + Slave。是一种去中心化模式。支持动态扩容,Cluster具备哨兵和主从切换(故障转移)能力。但相对运维复杂,只能用0号数据库。另外Redis Cluster最强大的地方是,扩充了写入的能力。哨兵模式中仍然是只有一个主库可以写入。而Redis Cluster通过引入代理,将key分到不同的槽,并映射到具体的Redis服务器上。由此提高了整体的写入能力。
- Redis的主从同步延迟如何解决
- 使用info指令监控主从同步情况,或者使用另外的客户端监控。在必要的时候发出警报,增加网络带宽,增加主从同步线程,换更强的电脑。
- Redis实现分布式锁有那些方案
- 从setnx、到set加nx参数、再到lua,都会有一些问题(主要是锁是否能完美设置过期)。注意这些方案中,value都应当具备唯一性,这样才能确定当前的锁是否是自己上的。比较好的方案可以参考Redisson框架,加锁后使用守护进程,定期查看线程是否完成业务,如果没有完成,再用expire指令延长锁的过期时间。如果应用在Redis集群中,还需要再加入分布一致性的机制(Redlock),单独建立一个多个redis(大家都是master)的集群。避免传统主从复制模式下,单一redis master挂掉之后,未完成锁数据主从同步的节点升级为master,破坏锁的安全性。这些也有Redisson提供支持。
- 参考7种Redis分布式锁方案
- Redis支持事务吗?
- 支持,但是不是传统意义上的事务。它的事务支持隔离性(事务执行期间不会被其他指令打断)。但并不保证持久性(显然)、一致性(因为没有回滚机制,执行前后的数据状态可能被打破)以及原子性。
- Redis的事务由multi指令开启,插入多个指令,并由exec执行。本质上是将多个指令传递给Redis中的事务指令队列,并由exec通知服务器执行。
- 提交指令如果有静态问题,则exec会直接失败,拒绝执行。提交的指令如果在运行期报错(内存、错误的指令和key等),则该条失败,但仍会继续执行。也正因如此,并不保证原子性,一批事务指令,可能部分成功。
- 使用WATCH能一定程度上加强事务的安全性。在执行exec之前,如果watch的key发生变化,则该事务不再执行。
- 如果对修改有一些特殊的需要,还可以使用Redis + Lua的方式来实现原子指令,当然这个事务的原子性也是值得思考的(看你自己的Lua脚本了)。
- 参考不支持原子性的 Redis 事务也叫事务吗?、Redis中的原子操作(2)-redis中使用Lua脚本保证命令原子性
- Redis有哪些线程
- 在高版本中,Redis为了避免网络I/O带来的瓶颈,引入了专门处理发送数据的线程池。从此,Redis可以分为三个大类。主线程,处理连接、读事件,以及将各类写入事件发送到队列。后台线程(三个,分别是异步关闭、aof刷盘、定期惰性删除)。I/O线程(默认3个)。
- Redis的混合持久化有什么优缺点
- 在AOF重写时,会先保存一份RDB,再保存后续追加的AOF日志。混合持久化结合了 RDB 和 AOF 持久化的优点,开头为 RDB 的格式,使得 Redis 可以更快的启动,同时结合 AOF 的优点,减低了大量数据丢失的风险。缺点是AOF 文件中添加了 RDB 格式的内容,使得 AOF 文件的可读性变得很差。而且不兼容之前的Redis。
- Redis Cluster中的槽为什么是16383个
- Redis Cluster中Master扩充一般在1000个左右,16383个槽位仍然是足够使用的。另外Master节点之间通过gossip协议互相传递信息,以及发送心跳。在这个过程中会同步自己维护的槽的信息(bitmap),过大的槽数会明显提高通信时的数据量。
- Redis的LRU和LFU的实现方式?
- 由于常规的LRU、LFU需要额外的链表、Hash表,对Redis显然不适用。Redis使用的是近似LRU、LFU。也就是在每次随机选取的key中,用时间戳找出最久未使用(LRU)、用访问次数找出最少访问(LFU)。注意两种算法使用了同一个字段。
unsigned lru:24;但分别用了16位、8位。
- 由于常规的LRU、LFU需要额外的链表、Hash表,对Redis显然不适用。Redis使用的是近似LRU、LFU。也就是在每次随机选取的key中,用时间戳找出最久未使用(LRU)、用访问次数找出最少访问(LFU)。注意两种算法使用了同一个字段。
- 说一下MySQL的高可用架构
- 参考MySQL高可用
- MySQL的行锁有哪些,并发机制有哪些,以及MVCC的实现机制?
- 行锁都是基于索引实现的,并发机制主要有LBCC(基于锁)和MVCC(基于快照读和活跃事务表)
- 参考MySQL记录锁、间隙锁、临键锁
- MySQL的联合索引为什么需要遵守最左匹配?
- 在联合索引的存储过程中,是按照联合索引从左到右的字段,去分层组织分支节点。例如第一层是针对第一个字段,进行分支。第二层的分支节点,可以同时针对第一、二个字段,并且在在第一个字段相同的情况下,若干个分支节点之间的第二个字段也是是有序的。
- 在这种实现的过程中,就会发现,如果没有满足最左匹配原则,那么都无法在最初分支节点上确定分支选择。也就无法利用这个联合索引了。但要注意的是,MySQL中有查询优化器explain,所以sql语句中字段的顺序不需要和联合索引定义的字段顺序相同,查询优化器会判断纠正这条SQL语句以什么样的顺序执行效率高,最后才能生成真正的执行计划。只是如果完全缺少字段的话,优化器也无力回天了。
- 参考数据库常见知识点总结-最左前缀匹配原则、EXPLAIN 命令详解
其他中间件
- kafka为什么读写性能可以很高?
- pagecache的原理。按照4k一个page的方式组织buffer cache,每一个buffer cache是实际指向磁盘的一个block了,cache提高性能的方式靠预读,第一次读miss会同步读取后面的几个block,第二次读取如果没miss,那么继续异步读取后面的block(扩大一倍),第二次读取如果miss,重复同步读取(说明现在是一个随机存取的情况)
- Kafka消息堆积怎么处理?
- 消费者端,增加消费实例,提高每批次拉取的数量。如果是比较费时的操作,可以先存在数据库中,然后逐条消费。
- 生产者端,支持熔断和隔离,当broker消息堆积,对生产者进行熔断。对key设置进行打散,使其分布更均衡。
- 服务端,合理设置partition的数量。
- MQ消息乱序如何结局
- 在上游生产者,控制发送缓冲区为1,强制按顺序发送。在下游消费者,使用单一消费者,按顺序处理。或者通过控制ID(hash),让同一系列消息进入同一个队列和消费者。
- 另外也可以通过服务内进行重排序。
- 也要注意幂等,以免重复消费。
- kafka和rocketmq的选型原因?
- kafka是生产者、消费者、Kafka集群(Broker),基于Topic和Partition。每个Topic可以有多个Partition,一个Partition就是一个文件夹。Partition会在多个Broker节点上复制(形成replica),保证数据一致性和高可用。
- RocketMQ架构稍微复杂,有NameServer集群(管理Broker)、Broker、生产者/消费者。Nameserver负责服务注册和发现。RocketMQ也是基于Topic和Partition的数据模型(叫做MessageQueue),但它采用了一种主从复制的机制,确保了数据的高可用性和容错性。
- Kafka吞吐量更高、RocketMQ延迟稍低。RocketMQ通过采用Zero Copy技术和缓存池技术来降低延迟,而Kafka则通过批量发送和异步处理的方式来提高吞吐量,但相应的会增加一定的延迟。而且RocketMQ是有推送模式的(虽然是包装了pull的本地线程),也会稍微降低延迟。
- Kafka使用分布式协调机制,确保消息在生产者/消费者之间的顺序,RocketMQ则需要Producer进行消息排序,一定程度上影响性能。
- Kafka消息事务不如RocketMQ。Kafka的消息事务需要自行实现。而RocketMQ应用本地事务和发送消息操作可以被定义到全局事务中
- Kafka的topic/partition模型,会导致其不适合于过多topic的场合。顺序读写会变成随机读写。RocketMQ更适合此类场景。RocketMQ采用的是混合型的存储结构,即为Broker单个实例下所有的队列共用一个日志数据文件(即为CommitLog)来存储。而Kafka采用的是独立型的存储结构,每个队列一个文件。单一的混合日志文件并不能降低延迟。RocketMQ的具体做法是,使用Broker端的后台服务线程ReputMessageService不停地分发请求并异步构建ConsumeQueue(逻辑消费队列)和IndexFile(索引文件)数据(虽然是随机,但是随机批量读取是好于Kafka的随机写入的)。ConsumeQueue是消息的逻辑队列,相当于字典的目录,用来指定消息在物理文件commitLog上的位置。其中包含了这个MessageQueue在CommitLog中的起始物理位置偏移量offset,消息实体内容的大小和Message Tag的哈希值。对于这两个文件再进一步使用PageCache和MMap文件映射,提高响应速度。
- 参考kafka和rocketmq区别对比、RocketMQ核心原理、RocketMQ的消息存储基本介绍
- RocketMQ的消费顺序一致性如何保证:
- 生产侧:在提交时有一个MessageQueueSelector,输入是可用MessageQueue,投递消息和附加参数,可以根据需要实现相应的逻辑,返回想要投递的MessageQueue。对于需要保持顺序性的业务消息,可以通过Hash等方式,将他们分配到同一个MessageQueue。
- 消费侧:广播模式(一个消息投递到多个消费者)、集群模式(一个消息最多投递到一个消费者)。集群模式中通过AllocateMessageQueueStrategy接口,对于给定的消费者分组、消息队列列表、消费者列表,决定消费者和消费队列的对应关系。
- 参考《深入理解RocketMQ》- MQ消息的投递机制
在不需要考虑顺序性的情况下,可以做很多优化,比如选择就近的机房,选择延迟最低的消费者、MessageQueue。
- 什么是RocketMQ支持的事务消息?
- 在一些应用场景下,生产者向消息队列上传消息也需要引入一个事务,此时可以提交一个半提交消息,并继续完成一些本地事务,如果本地事务成功,则正式提交消息,允许下游消费
- 参考RocketMQ官方文档:事务消息
- 说一下对Zookeeper的了解?
- ZooKeeper 是一个典型的分布式数据一致性解决方案,分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。通过Zab协议保证一致性。Zab(Zookeeper Atomic Broadcast)是为ZooKeeper协设计的崩溃恢复原子广播协议,它保证zookeeper集群数据的一致性和命令的全局有序性。
- Zookeeper有一些特别明显的缺点。复杂的集群管理、性能瓶颈、数据存储限制(每个 znode 的数据容量有限)、客户端实现复杂、故障恢复时间(如领导者选举时)可能需要一定时间才能恢复服务,影响系统的可用性。
- 如何用zookeeper做分布式锁?
- 大体的流程就是先创建一个持久父节点,再在该节点下,创建临时顺序节点,找出最小的序列号,获取分布式锁,程序业务完成之后释放锁,通知下一个节点进行操作,使用的是watch来监控节点的变化,然后依次下一个最小序列节点进行操作。
操作系统
- 什么是进程优先级反转?
- 高、中、低优先级在高等待低时,出现的中先运行的情况,解决方法:优先级继承,高等待低时,将低优先级提高优先级,先执行,之后再恢复;优先级天花板:当进程申请某项共享资源时,都直接默认将所有可以访问到该资源的任务优先级提到最高,简单粗暴,等执行结束再恢复。
- 虚拟内存的一次完整访问过程?
- 每个进程都有自己的一个页表,页表的起始地址放在进程的PCB中,当某个进程运行时,将该起始地址放在页表基址寄存器中(PTBR)。该地址是物理地址。
- 以32位机器使用两级页表为例,从PTBR中获取页表基址,加载的是一级页表,也就是页目录PGD(Page Global Directory),此后用逻辑地址前10位,索引到页目录项,再加载对应的二级页表PTE(Page Table Entry),最后用中间十位索引到页表项,加载对应页表。最后加上页内偏移就访问到了实际的内存位置。
- 内存碎片的产生原因?
- 内部碎片,没有完全使用分配的内存,外部碎片,未分配的连续内存区域太小,无法满足分配请求。
- 解决办法,通过分页式的虚存管理。将物理内存分别分配,大幅减少了外部碎片。
- 信号和信号量的区别?
- 信号是处理异步事件的一种方式,通信使用。信号量(semaphore)是同步互斥的机制,负责协调并发环境下的资源使用。
- 管道的分类和使用限制?
- 有命名管道和匿名管道两种。但都是单向的,一端读另一端写。
- 无名管道pipe只在有血缘关系的进程之间使用,因为其能共享文件描述符表,是一种存在于内存的特殊文件。命名管道fifo则可以用于任意进程间通信,在磁盘上会有该文件的标志,但是仍然会使用内存存储,当内容超过大小限制时会写磁盘。
- select、poll、epoll的区别?
- select和poll比较接近,只是使用的描述符表结构不太一样,支持的数量有差别,fd_set / pollfd,而且每一次调用select需要把fd_set拷贝到内核空间。
- epoll更高端,开辟一段事件空间。使用epoll_ctl注册对应的文件事件的回调,将可以交给用户处理的放入ready队列。epoll_wait内取出一个可用的,并使用内存映射mmap拷贝到用户空间。
- CAS的原理?是悲观锁还是乐观锁?二者优缺点
- 通过CPU的CAS指令、内存总线锁、缓存锁MESI协议共同保证。是乐观锁
- 无法解决ABA问题,自旋时有CPU开销,只能保障单个变量
- 内核对象资源是什么?
- 操作系统内核需要维护的一些对象,比如进程、线程、信号量、文件描述符,这些内容可能在不同的内核模块、用户进程中都有引用,内核使用引用计数来维护,当计数归0才会将其删除。
- 什么时候会发生栈溢出?
- 局部数组过大、递归层数过多、指针/数组越界。
- 硬链接和软连接的区别
- inode表示的是一个文件,它是用来索引文件数据的。根据文件大小的需要,索引可能分成多个层级。
- 硬链接是创建新的目录项指向同一个文件的inode。文件本身就是一个硬链接。inode会记录这种指向的数量。只有为0才能真正删除。
- 软链接是创建新的inode,指向一个保存目标文件路径的文件。是真正的间接引用。
- 参考知乎-文件系统和I/O、Linux文件系统中的硬链接及常见面试题
- 页表存储在用户空间还是内核空间,在使用时是否需要陷入内核态
- 存储在内核空间,但是普通的访问由MMU硬件完成,不需要陷入内核态,只有缺页中断时需要陷入
- 参考知乎:页表到底是保存在内核空间中还是用户空间中?
- Linux操作系统提供哪些同步机制
- 原子操作、读写信号量、spinlock、大内核锁(已废弃)、读写锁、大读者锁(已废弃)、RCU锁(类似双缓冲区)、顺序所(写优先,读时不上锁,如果seq id发生变化,重新读取)
- 参考一文搞懂Linux内核同步机制原理与实现(上篇)、(下篇)
- 什么是写时拷贝?
- Linux在创建子进程时,会将地址空间和子进程进行共享(通过复制页表的方式),如果后续不进行重新映射的话,那么此时子进程可以以只读的方式直接使用原先的内存中的数据。但如果父进程此时修改了,那么系统会为子进程单独复制一份并修改页表(物理内存)。注意写时拷贝技术只是降低了在需要共享数据情况下,创建子进程的延迟(避免拷贝全部数据),但这个延迟只是均摊到了后续的每一次修改中。整体来看吞吐率并不一定上升。
- 消息队列和共享内存的区别?
- 共享内存拷贝次数少,效率高,适合大量数据,但需要额外加锁保证安全。消息队列可以点对点也可以广播,不需要考虑并发安全,拷贝次数多,适合有顺序性的处理场景。
- 参考消息队列和共享内存的区别
- 共享内存mmap和shmget的区别?
- mmap的设计并不完全是为了共享内存,更多的是给出一个通过内存读写操作文件内容的方式。因此其可用的大小也更大,可以超过主存的大小。mmap下,各进程映射文件的相同部分可以共享内存。
- shmget是对内存的共享,因此其大小不可能超过内存。而且在机器挂掉时会丢失数据。
- 消息队列和管道的区别?
- 对匿名管道(要求进程之间有父子关系)来说,消息队列提供了一种在两个不相关进程间传递数据的简单有效的方法。对命名管道(基于文件系统)来说,消息队列独立于发送和接收进程而存在,这消除了在同步命名管道的打开和关闭时可能产生的一些困难。
- 参考管道和消息队列的区别
- 信号和信号量的区别?
- 记住英文名字,一个是signal、一个是semaphore。信号主要用于进程间的异步通信,而信号量主要用于控制多个进程对共享资源的访问。信号量是一种计数器,用来控制对多个进程/线程共享的资源进行访问。
- 如何利用CPU Cache来优化程序?
- 利用时间、空间局部性原理,优化数据结构布局(提高局部性)、使用缓存友好的算法、考察硬件的Cache规模和类型,尽量避免随机访问。
- 什么是假共享?
- 当多个线程在不同的CPU核心上访问同一缓存行的不同部分时可能会发生假共享,此时缓存行可能反复失效(标记为独占、脏等),这会降低性能。通过调整数据结构的布局或使用填充技术来减少假共享。
- 什么是内存屏障?
- 相比于CPU和编译器屏障(防止指令重排),内存屏障是对Load和Store进行保证。一共有四种,LL、LS、SL、SS。分别阻止后者重排到前者前面。
- Linux中的进程和线程的区别?
- 在 Linux 中,线程实际上是通过轻量级进程(LWP)实现的,Linux 对线程和进程的区分不像其他操作系统那样明显。进程和线程都使用相似的内核结构 “task_struct”。这意味着在 Linux 中,创建和管理线程几乎与进程一样高效。此外,Linux 提供了一种称为 clone() 的系统调用,它允许调用者指定子任务与父任务共享的资源范围。通过这种方式,clone() 可以用来创建线程(较少的资源共享)或完整的进程(不共享资源)。
- 进程最初的线程是主线程,其pid是同进程的其他线程的
tgid。这个变量用来记录所属的进程。 - 创建进程用fork、创建线程可以用clone,但是底层最终都是通过do_fork、copy_process来完成的。二者在调用 do_fork 时传入的 clone_flags 里的标记不一样。clone可以控制更多的选项,决定和父进程共享的内容(地址空间、文件系统信息、文件描述符表)
系统运维
- 如何查看线程级的CPU等资源占用情况?
- 使用htop,或者在top中输入H
- 如何查看进程执行历史,退出状态
- 安装psacct工具集,使用其中的accton指令,开启进账记录,将会记录
- 对于信号,还可以通过安装audit,开启audit服务,来统计发送的信号情况
- 对于用户的操作执行历史,可以通过last、history来查看
- 如何在代码中查看CPU/内存等资源的使用情况
- 查看linux的虚拟文件系统/proc,尤其是各个PID下面的stat,即/proc/%PID/stat,里面包含了指定进程的各种资源利用信息
- 程序CPU占用高,如何定位问题?
- 使用perf对cpu执行情况进行采样,记录函数调用关系、调用占比等。还可以生成火焰图辅助
- 参考理解perf:怎么用perf聚焦热点函数?
数据结构
- 散列冲突如何解决?
- 链表法、开放寻址法(在碰撞位置向后按一定规则寻找一个空闲单元,主要的问题是删除的时候需要特殊处理,不能直接删)、再散列(碰撞时换用另一个散列函数,直到不再冲突)
- AVL和红黑树的优缺点?
- AVL树平衡性更高,因此查询有一定优势。但是其平衡维护时最坏的情况可能需要调整到根节点,删除操作性能一般,适合查询极为频繁,而插入删除修改很少的数据场景
- 红黑树平衡性稍差,因此查询有一定劣势。但其平衡维护最差也是固定调整次数,删除操作性能较好,更稳定。在Linux内核、STL等多个场景下使用。
- 无锁编程的常用方法?
- 原子操作、乐观锁、CAS指令、Read-Copy-Update、无锁数据结构
算法/数学题
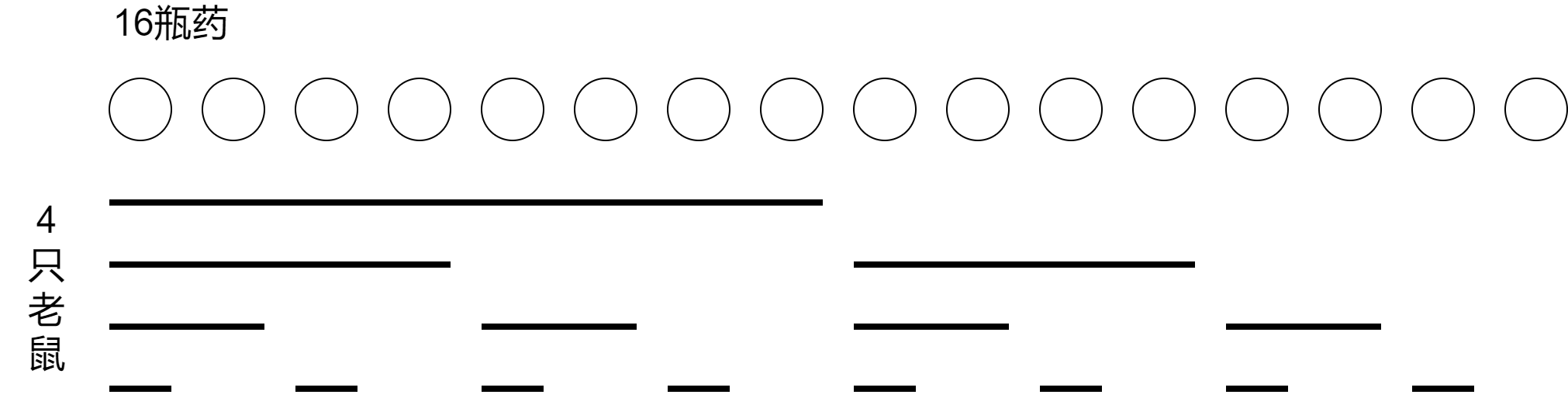
- 1000瓶药,1瓶有毒,会在24h时死亡,需要多少小白鼠才能在第24h的时候找出来?
- 串行:如果不考虑第24h找到这个要求,可以用传统的查找方式,即串行的二分查找,首次让小白鼠喝500瓶,然后根据结果选择下250瓶喝哪些。
- 并行:从题目可知只能进行一次测试,即只能通过一批死亡测出结果。实际上也可以并行的做二分。这里简化为1024瓶药,需要10个bit来表达,编号后,第一瓶是0000000000,最后一瓶是1111111111。令第i个小白鼠,喝下所有第i个bit为1的药。就能实现。下图以16瓶药为例子,说明4个老鼠如何能做到一次性检测。
- 1个袋子、有100个黑球、100个白球,每次取出两个,如果颜色相同,则放回一个黑球,颜色不同,则放回一个白球,问最后剩下一个黑球的概率?
- 看似复杂,但只要分析一次操作的所有情况就能进行总结:即每次操作,减少一个黑球,或者少两个白球但多一个黑球。从计算机的角度来看,这是归纳出了一个原子操作。
- 在这个前提下,实际上很快就能发现,游戏存在两种结束情况:只要白球初始值是偶数,则袋子内最后的球数是一定可以归零的;否则最后会剩余一个白球
- 如何计算无限循环小数之间的高精度乘法
- 首先做一个高精度乘法、高精度除法(竖式就可以)
- 其次要知道无限循环小数是有理数,而有理数一定可以表示为$n/m$的形式,其中n和m都是整数。对于$123.56(789)$括号内是循环节,可令$x=123.56(789)$,进一步可得$10000(x-123)=56789.(789) = 100x + 44433$,化简就可以得到结果。
- 之后就可以对分子、分母分别相乘,再做一次高精度除法,直到计算出循环节。
硬件
- 什么是local apic?
- PIC(Programmable Interrupt Controller可编程中断控制器)是一个有相当久历史的硬件,它对外负责连接外部各种容易产生中断的设备,对内和CPU相连。
- 随着中断类型的增加和多CPU的出现,推出了更高级的APIC技术(Advanced PIC),它分为IO APIC和Local APIC两部分,前者就一个,仍然负责和外设通信,后者每个CPU内部集成一个,各个Local APIC、IO APIC一起通过系统总线相连。
- IO APIC可以发送中断给指定的Local APIC,Local APIC之间也可以相互发送中断
注意多CPU和多核心并不完全一样,多CPU指的是有多块CPU芯片,多核心则是一个CPU芯片中集成多个物理核心。服务器上经常有多路CPU。
- x86架构的内存管理?
- x86架构的内存管理是段页式内存,这里的段对应的是原本的分段式内存管理(程序段、数据段)、页则是代表内存分页管理,这两者结合起来就是段页式。按照从段到页的阶段,地址也分为虚拟地址、线性地址、物理地址。
- 逻辑地址包含段选择器和偏移两个部分,用这两部分去描述符表(有全局和局部两种)中查找对应的线性地址,用线性地址查找到属于自己的页表,随后进行页式存储管理
- 但对于不同的操作系统,也未必真的按照段页式编写内存管理部分,比如Linux就选择将所有的内存编入同一个段,也就是地址从一开始就是线性地址,完全使用分页管理
- 分支预测的原理?
- 静态预测,按照固定的分支预测
- 动态预测,维护一个历史分支记录,动态改变预测
- 还有更多的预测方式,如两级自适应、局部&全局分支预测、神经分支预测
- 超标量、超线程技术是什么?
- 超标量的实现:CPU的一个物理核心内部实际也有由多条流水线,往往还会结合指令乱序发射、多发射技术(有多条流水线,当然可以将没有依赖性的指令同步执行),最终达成在一个时钟周期内执行多条指令的能力
- 超线程的实现:增加了取指器和译码器,使得能让多个线程在一定程度内共享一个CPU的资源,减少流水线的空闲
其实从某个角度来说,超标量和超线程等技术,也是导致内存一致性问题的原因
- Cache是什么,L1、L2、L3的速度是什么样的?
- 一般来说,L1/L2 缓存是一个物理核自己有一个(L2有可能共享),都是SRAM,L1大约3个周期(追求低延时),10KB量级,L2大约10个(量级)周期(追求带宽),百KB量级。
- L3是所有核心共享的,大约25周期,容量更大,能达到数十上百MB,可能是SRAM、STT_MRAM、eDRAM来实现。
- 内存的速度更慢,可能达到100周期。
- 参考细说Cache-L1/L2/L3/TLB
- 了解服务器的CPU架构吗?
- 这里问的是SMP、NUMA、MPP。分别是对称多处理器,所有处理器共享同一组资源(总线,内存等),由于共享带来冲突,所以SMP最多也就是2~4个CPU。而在NUMA中,每个CPU模块内先由多个CPU(如4个) 组成,并且具有独立的本地内存、 I/O 槽口等。再进一步通过通信将CPU模块连接起来,允许对远程CPU模块下的内存进行访问,扩展性更强了, 但是对远程内存的延迟过大,导致整体性能随扩展上升并不是线性的。而MPP 提供了另外一种进行系统扩展的方式,它由多个 SMP 服务器通过一定的节点互联网络进行连接,协同工作,完成相同的任务,从用户的角度来看是一个服务器系统。其基本特征是由多个 SMP 服务器 ( 每个 SMP 服务器称节点 ) 通过节点互联网络连接而成,每个节点只能访问自己的本地资源 ( 内存、存储等 ) ,是一种完全无共享 (Share Nothing) 结构,因而扩展能力最好,理论上其扩展无限制。
- 参考五分钟理解服务器 SMP、NUMA、MPP 三大体系结构
- Write Through和Write Back是什么?
- 保持内存和Cache数据一致性的办法。Write Through是写回,同时写缓存和内存,性能低。Write Back则是写缓存,并由缓存协议进行写内存,以及保证数据一致性。
- 简述一下MESI协议的状态转移?
- MESI中对于每一个缓存行,有MESI四种状态(修改、独占、共享、无效)。对于每种状态,存在在Local Read/Write(本地核心读写),Remote Read/Write(远程核心读写),四种转移。
- 简单来说,Local Read可能从I到E/S,或者保持不变。Local Write可能从所有状态到M。Remote Read可能从E/M到S。Remote Write则是会从E/S/M到I。
- 从状态转移可以看出,MESI只能保证一个操作的原子性(加载、写入),并不能提供多个动作的原子性,因此对于多个核同时进行i++这种操作,是会丢失一些更新的。
- 参考小林coding:用动图的方式,理解 CPU 缓存一致性协议!
- 什么是Cache的Store Buffer?
- 缓存的更新速度并没有很快,在CPU和L1之间引入Store buffer,显然是每个核心有自己的Store Buffer,对cache line的写操作进行优化。
- CPU的写操作写入Store Buffer之后就返回,同时向其他核心发出Invalidate的消息。而Store Buffer在收到Invalidate的ACK之后,将数据写入cache line。
- 核心在读取缓存前,要先扫描自己的本地Store Buffer,确定是否有目标行,如果有的话,直接使用。此时数据还没刷到缓存。
- Store Buffer不能跨核心访问。在等待其他核心将Store Buffer写入缓存之前,其他远程核心只能确定cache line已失效。
- 什么是Invalidate Queue?
- Store Buffer 容量是有限的,当Store Buffer满了之后CPU核心还是要卡住等待Invalidate ACK。所以要降低ACK的响应延时。而接收方响应Invalidate ACK耗时的主要原因是核心需要先将自己cache line状态修改I后才响应ACK。如果一个核心很繁忙或者处于S状态的副本特别多,可能所有CPU都在等它的ACK。
- CPU优化这个问题的方式是引入Invalid queue,CPU核心先将Invalidate消息放到这个队列并立刻响应Invalidate ACK,但不马上处理,消息只是会被推invalidation队列,并在之后尽快处理。
- 因此核心可能并不知道在它Cache里的某个Cache Line是Invalid状态的,此时它的Invalidation队列包含有收到但还没有来得及处理的Invalidation消息。
- CPU加载一个内存数据的全过程?
- 地址转换:如果启用了虚拟内存,CPU 使用内部的内存管理单元(MMU)将虚拟地址转换成物理地址。
- 缓存查询:CPU 检查数据是否存在于它的缓存中。多级缓存结构通常按照 L1、L2 和 L3 缓存的顺序查询。
注意查看TLB和Cache都是有可能的。看系统支持的是物理Cache还是逻辑Cache。即是使用虚拟地址访问缓存还是使用物理地址访问缓存。两者各有优劣,一个是多一次地址转换,一个是需要存储进程信息。
- 缓存命中和缺失:
- 命中:如果要加载的数据已在缓存中,CPU 会立即读取数据(缓存命中)。
- 缺失:如果数据不在缓存中(缓存缺失),则进行更深层次的查询,可能需要查询其他级别的缓存,最后可能需要从主内存中读取。
- 从内存读取:如果缓存中都没有找到数据,CPU 然后从物理内存地址读取数据。
- 写入缓存:读取的数据被加载到缓存中以便未来快速访问(根据缓存替换策略,一些旧的数据可能会被替换)。
- 数据返回给 CPU:一旦数据可用,它就被送回到 CPU 的寄存器中,供指令使用。
- 如何提高缓存友好性?
- 数据结构上:保证数据按照线性和顺序方式被访问(例如,按数组顺序访问)。
- 执行代码上:尽量减少每个数据操作所需的数据集大小,使当前访问的数据集可以适配于缓存。减少循环嵌套的深度,或更改循环的顺序以保持数据的局部性。
- 说一下虚拟内存?
- 是一个硬件和操作系统提供的特性,它允许程序将数据和代码放置在看似连续的地址空间中,这个空间被分割成大小相同的页,实际上数据可能分散存储在物理内存的不同位置,甚至存储在磁盘上。
- 通过段页式存储,消除了外部碎片(仍有可能存在内部碎片)
- 虚拟内存的好处包括:
- 内存管理简化:程序也可以作为独立的、大小相同的页进行管理。
- 内存保护:每个程序拥有独立的地址空间,这增强了安全性。
- 运行更多应用程序:即使物理内存不足,也能够通过交换页到磁盘的方式运行更多应用程序。
- 每页的大小因操作系统和硬件而异,但通常大小是4KB或更大,例如2MB的大页。
其他
- 大尾端是什么?如何判断?
- 大地址在数字尾端。0x12345678,如果大地址位是0x78,则是大尾端
- 网络续默认都是大尾端
- 常用的CPU中,x86是小尾端、arm是大尾端
- 另一种标准翻译是大端序(Big Endian)、小端序(Little Endian),大端序就是大尾端,小端序就是小尾端。
- OLAP和OLTP是什么,有什么区别?
- OLTP(on-line transaction processing)翻译为联机事务处理, OLAP(On-Line Analytical Processing)翻译为联机分析处理,从字面上来看OLTP是做事务处理,OLAP是做分析处理。从对数据库操作来看,OLTP主要是对数据的增删改,OLAP是对数据的查询统计分析。二者在技术栈、系统目标、服务对象、时间敏感度、业务阶段都有一定区别。
- 谈谈秒杀系统的设计?
- 核心思路就是对流量做验证、限流、拦截,必要的时候对服务进行降级,模糊查询结果。
- 前端:提交按钮限制提交次数,参与活动必须登录,前端页面做成静态、本地缓存,避免对前端服务器产生压力
- 网关:控制同一用户的流量,控制同一ip的流量
- 业务:使用消息队列限制业务量,利用缓存加快查询速度,定期更新缓存数据
- 数据库:根据流量情况,可能对数据库进行单独创建,分库分表,提升数据库处理能力。上锁、事务,保证不超卖。
- 并行计算的模型有哪些:
- 常见的并行计算模型有:BSP、PRAM、LogP、C3、BDM
- 什么是熔断、限流、降级?
- 参考10张图带你彻底搞懂限流、熔断、服务降级。简单来说,限流是为了避免流量超过服务能力带来崩溃,主动进行的对流量速率加以控制的方法。熔断则是发现错误状态下,避免服务异常,比如发现某个下游服务异常,超过一定数值,就应该断开对该服务的访问。降级则是更高层的系统设计角度,在服务发生任何异常的时候,配置的一些处理策略,比如被限流时、被熔断时,以及当系统检测到服务压力,主动关闭一些非核心功能的情况。可以说限流和熔断都是降级的一种手段。
- 谈谈悲观锁和乐观锁
- 在不同的领域中,悲观锁和乐观锁有不同的含义。在操作系统层面,CAS代表乐观锁,可以短暂等待获得,悲观锁则是常规的重量级锁
- 在分布式系统中,乐观锁则是指每次都尝试修改,在提交时可以通过对比快照数据,来确定是否能够提交。而悲观锁则是每次都一定要锁定再修改。
- 如何对性能问题进行定位
- 从不同维度去考虑:CPU(线程池配置、计算密集型)、内存(Java这边调优很多,堆栈元空间内存溢出,GC)、网络(端口、TIME_WAIT)、中间件(分布式锁、MySQL索引问题)、其他软硬件资源(磁盘等)
- 可以具体结合火焰图,定位热点函数,过深的调用堆栈等
- 参考Java 应用压测性能问题定位经验分享
非专业内容考察
- 兴趣爱好
- 职业规划
- 问自己的缺点
- 说一些可以克服的,比如技术基础需要加强、工作经验有一定欠缺、对待工作有时过于细致影响效率、爱好有些分散的缺少拳头爱好
- 被发现问题立刻承认,没必要遮掩
- 一定要准备一份英文的自我介绍
- 为什么从之前的公司离职
- 技术追求、职业规划、生活工作
推荐阅读
参考
- 知乎:后端都要学习什么?
- MyBatis官网
- MySQL8.0 存储引擎综述
- 优先级反转
- 内存访问全过程
- 操作系统——页表寻址
- MySQL中NULL对索引的影响
- OLTP与OLAP的关系是什么? - Kyligence的回答 - 知乎
- 【x86架构】内存管理
- 理解X86的内存管理
- 段式、页式内存管理以及linux采用的方案图解
- 知乎专栏:计算机中断体系一:历史和原理
- APIC的那些事儿
- 【并发基础】CAS(Compare And Swap)操作的底层原理以及应用详解
- 秒杀系统设计、【秒杀抽奖】秒杀系统设计、这一次,彻底弄懂“秒杀系统”
- linux专题 1:page cache
- WIKI 分支预测器
- 内核笔记(七)——内核对象(Kernel object)机制
- 并行计算模型
- static_cast, dynamic_cast和reinterpret_cast的区别
- 红黑树与AVL树,各自的优缺点总结
- 关于AVL树和红黑树的一点看法
- 去BAT,你应该要看一看的面试经验总结
- C++LinuxWebServer 2w7k的面经长文(上)
- C++LinuxWebServer 2w7k的面经长文(上)
- 知乎-卢新来:高并发的一些总结
- Leetcode——C++突击面试