
边学边用linux-命令行篇
目录
需要熟练掌握命令行是Linux系列系统最大的特点之一。本文从实用角度出发编写。
Bash快捷键
Bash快捷键的主要目标是快速输入指令,调整指令。这里记录一些使用内容
| 快捷键 | 作用 |
|---|---|
| Ctrl + a/e | 移动到行首/行尾 |
| Ctrl + h/d | 向前/后删除一个字符 |
| Ctrl + b/f | 向前/后移动一个字符 |
| Alt + b/f | 向前/后移动一个单词 |
| Ctrl + u/k | 删除到行首/行尾 |
| Ctrl + r | 搜索命令历史 |
| Ctrl + r/R | 搜索命令模式下,向前/后遍历 |
核心指令
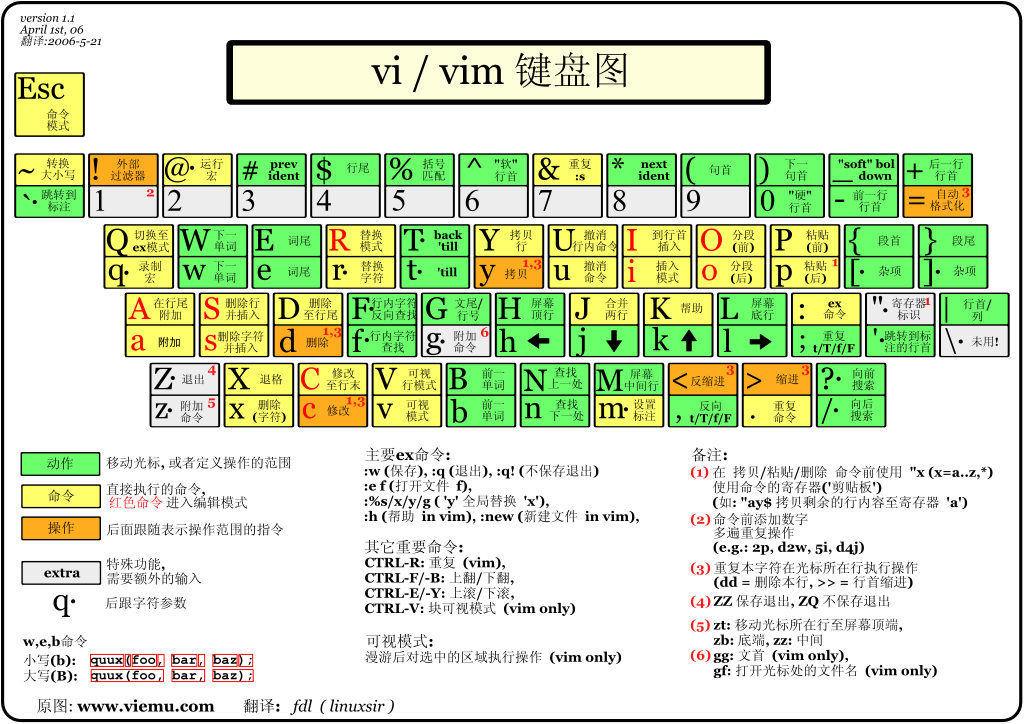
vi/vim
-
关系:vim是vi的继承和发展,下面以vim为主,和vi不兼容处会进行标注
-
Command(命令)模式
目标 按键 说明 切换模式 iao/IAO 于光标前后、行前后、行上下切到输入模式 R 替换模式 : 切到最后行模式 小v 可视模式 大V 可视行模式(一行全被选中) Ctrl+v/V 可视块模式(选中的是一个跨行的矩形) 快速移动 w/W 向后一词 b/B 向前一词 {/} 段落首尾 hjkl 左下上右 Ctrl+f/d 向下一页半页 Ctrl+b/u 向上移动一页半页 Ctrl+e/y 上滚下滚(光标仍在原行) ^ 0 | 移动到行首 $ 行尾 e/E 词尾 f/F 当前行向后向前查询字符(字符由下一个输入给出) H 移动光标至屏幕顶行 L 移动光标至屏幕底行 M 移动光标至屏幕中间行 数字+空格 向后移动若干字符 G 最后一行 gg 最初行 nG 移动到第n行 n+回车 向下移动n行 修改 x/X 向后/前删除 r 替换字符(光标处替换为下一个输入字符) p/P 向后/前粘贴 s/S 删除当前字符/行并切到输入模式、 J 合并两行 复制 y拷贝 拷贝(yy当前行、nyy复制n行、yG复制当前行到末行、y0复制当前字符到行首、y$复制当前字符到行尾) Y 整行拷贝 搜索 /word 向后搜索 ?word 向前搜索 n/N 下/上一个搜索结果 动作变更 u 撤销 U 行内撤销 Ctrl+r 重做(u的反向) . 重复上一动作 数字+命令 重复执行命令 -
Insert(输入)模式
- 在此模式下可以像图形化文本编辑器一样,向文件输入字符
-
Last Line(最后行)模式
- 快速移动:数字(移动到该行)
- :wq、q、q!:保存退出、退出、不保存退出
- :wq 等价于 ZZ(命令模式下)
- :wq 等价于 ZQ(命令模式下)
- :w [filename] 写入指定文件
- :r [filename] 插入指定文件的内容到当前文件
- :! [command] 暂时返回shell,执行command
- :n1,n2s/word1/world2/g 替换n1行到n2行之间的word1为word2
- 其中n2可用$符号代表最后一行,1,$也直接等价于%
-
实用配置:
- 显示行号 :set nu
- 取消行号显示 :set nonu
-
名词解释
- 段落:一系列非空行是一个段落
- 句子:以. ! ?结尾的,且后继字符为空格、水平制表符、换行符的一系列单词
- 单词:默认情况下,是由字母、数字、下划线和其他部分非空字符(如~)组成的连续字符串,其他任何字符都视作分割
awk
-
三剑客之一:主要使用方式是预处理+逐行处理+最终处理,常用于格式化输出、统计等工作。因为可以编程,我觉得是唯一真神。参考使用案例
-
基本结构
awk [各命令行参数] 'BEGIN{} {/pattern1/ action1;action2;} \ {/pattern2/ action3;action4;} ... END{}' {filenames}- awk通常逐行读入并根据各块内斜杠/对儿内的pattern进行匹配,每当匹配成功,执行对应块内的action,不同pattern之间互不影响
- BEGIN块最先执行、END块最后执行,其他各块之间按顺序依次执行
- action内容和脚本语言类似,有一套自己的语法
- 注意使用单引号',在单引号对儿内部,仍然可以使用双引号对儿"“代表内部是字符串
- awk强大的原因之一是,它的分支和循环语句可以基本以C语言语法看待,非常便于编写逻辑,唯一的难点是时刻记得
i和$i的区别,前面是变量,后面是用变量值去取列 - 输出时使用
print换行输出,使用printf不换行输出
-
pattern语法(正则表达式Wiki)
符号 描述 ^$ 行首尾定位符 . 匹配1个任意单个字符 * 匹配$[0,+\infty]$个前导字符 + 匹配$[1,+\infty]$个前导字符 ? 匹配$[0,1]$个前导字符 [] 匹配一次括号内某个字符 [^ ] 匹配一次括号内字符集以外的任意字符 () 匹配括号内的字符串整体 | 或,用于组合多种匹配情况 \ 转义 x{m[,[,n]]} 匹配$m$、$[m,+\infty]$、$[m,n]$次(需awk版本支持) [[:lower:]] 任意小写字母,参考POSIX字符组 注意只要正则表达式能成立(能匹配到该行的部分或全部字符),则会执行后续动作,即使匹配空。这点在使用*且不指定边界时应当尤其注意。
注意,
\d等转义字符并不是awk、sed支持的正则表达式语法,最稳妥的方式就是用[]去写 -
action语法
- 运算符:
符号 描述 = += -= *= /= %= ^= **= 赋值 || && 逻辑运算 ~ !~ 正则匹配、正则失配(用法见例子) < <= > >= != == 关系运算 + - * / & ! 加减乘除与非 ^ *** 求幂 ++ – 前后缀自增自减 $value 引用变量value <space> 字符串链接 ?: 三目运算符 in 数组中是否存在 - 内置变量:
名称 用处 $0 当前行(此次处理的输入) \$1~\$n 当前记录正则匹配的第i段 FS 字段分隔符 RS 行分隔符 NF 行内字段数 NR 行数 OFS 输出用的字段分隔符 ORS 输出用的行分隔符
注意只有$1等需要前置,其他变量不需要,就像是C、python中的变量一样使用即可。
- 控制语句
- 控制语句复杂时,建议单独创建文件,分多行书写,行尾不需要写;
- if、else、圆括号、花括号等同于C语言
- 支持for(;;)循环体、支持break、continue
- 支持for( a in b)循环
- 定义变量不需要写类型
- awk中的数组本质上都是map,可以使用字符串等做索引
- 函数定义
function name(arg1,arg2,...) { .... return ... }
- 运算符:
-
命令行参数:
- -F fs 或 –field-separator fs :给出后续输入文本的字段分隔符
- -f scriptfile 或 –file scriptfile :从指定文件中加载awk命令
- -v var=value 或 –asign var=value :定义变量
sed
- 三剑客之二:处理、编辑文本文件,和awk相比,更擅长修改文件。默认输出结果到控制台。
- sed是面向行的处理,读入每一行,保存到缓存区(模式空间),匹配并做相应动作,不会修改源文件。
- 所使用的正则表达式和awk的正则语法在大体上一致,也用斜杠对儿/pattern/作为表达式范围标志。但是有很多细节问题
- 对
|、{}、+、()等符号,使用其正则含义时需要转义。(在其他正则匹配中一般是不转义是代表正则含义)
- 对
- 基本语法
# 使用脚本,或脚本文件,处理输入文件 sed [-e <script>] [-f <scriptFiles>] [inputFiles] # 使用-n,不打印模式空间的内容,只会按照命令内容执行,输出很干净 sed -n xxx xxx # 注意因为{}在sed中有含义,所以在正则表达式内使用时,需要转义 # 这一点和awk不同,awk的正则表达式是在action前单独出现的,不需要对{}转义 # 例如打印能匹配连续两个数字的行 sed -n '/[0-9]\{2\}/p' - 动作
命令 功能 a 追加 c 更改 i 插入 d 删除 s 替换 p 打印 = 用于打印被匹配行的行号 n 跳到下一行 r 将内容读入文件 w 将匹配内容写入文件 y 一对一替换 q 退出 - 脚本结构:
- 不指定行的操作:触发条件(匹配,行) + 动作 + 动作参数 + 动作 + 参数…例如:
# -e 可省略 # 匹配123的行并增加hello sed '/123/ahello' test.txt # 最后一行添加hello sed '$ahello' test.txt # 替换语法s/x/y/,每行只替换第一个 sed 's/from/to/' test.txt # 替换,行内出现多次也替换 sed 's/from/to/g' test.txt # 替换,行内替换第2个匹配位置 sed 's/from/to/2' test.txt # 替换并写入新文件 sed 's/from/to/gpw output.txt' test.txt # 从input.txt读入内容到test.txt的第3行后 sed '3r input.txt' test.txt # 删除每行的最后两个字符 sed 's/..$//g' test.txt # a->A, b->B, c->C sed 'y/abc/ABC/' test.txt - 指定行的操作:运算符, ~ +
# 在第3行后添加新行2333 sed '3a2333' test.txt # 第3行插入hello sed '3ihello' test.txt # 第一行替换为hello sed '1chello' test.txt # 删掉奇数行(每两个删一个) sed '1~2d' test.txt # 删掉1到2行 sed '1,2d' test.txt # 打印匹配#的行及其后1行 sed '/#/,+1p' test.txt - 复合动作:花括号{}
# 删掉1到3行中匹配123的行 sed '1,3{/123/d}' test.txt # 打印最后一行的行号和内容 sed '${=;p}' test.txt # 匹配hello,并删除其下一行的内容 sed '/hello/{n;d}' test.txt - 取反:运算符!
# 删掉除了1,2行的所有行 sed '1,2!d' test.txt - 结合
# 匹配没有#号的行并替换@为# sed '/#/!s/@/#/g' test.txt - 多重编辑:注意前后顺序有影响
# 先删掉1至3行,再进行替换 sed -e '1,3d' -e 's/Rex/Lyc/g' test.txt
- 不指定行的操作:触发条件(匹配,行) + 动作 + 动作参数 + 动作 + 参数…例如:
- 参考:shell脚本-sed的用法、sed详解
grep
- 三剑客之三:强大的文本搜索工具,家族成员包括grep、egrep、fgrep,后两者只是前者的一种扩展。
- 匹配指定文件中的各行,默认打印匹配成功的行
- 默认使用基础正则表达式
- 基本语法
# 输入匹配用的正则表达式,以及待匹配的输入文件 grep expression files - 常用参数
参数 意义 -a 对二进制文件依然尝试匹配 -c 统计匹配成功的行数总和 -A n 显示匹配行和之后的n行 -B n 显示匹配行和之前的n行 -C n 显示匹配行前后各n行 -e expression 指定使用的匹配字符串 -E 扩展正则模式(和基础正则相比,转义的含义恰好相反) -f files 指定基础正则表达式所在文件,一行一个 -F 将表达式视为普通字符串,进行朴素模式匹配 -H 在打印匹配行前,额外显示匹配行所在文件 -i 忽略大小写 -l(小写的L) 不打印匹配行,只列出匹配成功的文件名 -L 列出无法匹配的文件名 -n 列出行号 -d read/skip/recurse 输入文件含有目录时,处理该目录/跳过/递归处理该目录 - 用例
# 在test.txt中查找hello grep hello test.txt # 使用基础正则查找hellohello grep "\(hello\)\{2\}" test.txt # 使用扩展正则 grep -E "(hello){2}" test.txt # 递归查找当前目录下文件,扩展正则匹配 grep -d recurse -E "(hello){2}" ./ - 参考:grep 命令
find & locate:
- find:相对较慢的通用查询方式,但可以指定不同属性查找文件,属性包括:名称、文件类型、文件大小、文件归属、文件权限、文件时间等等
# 基本语法 # 指定路径在前(默认从当前位置开始),指定搜索内容在后 find path expression -option [-print] [-exec -ok command {} \;] # 查找指定名称的目录 find ./ -type d -name Projects # 使用通配符 find ./ -name "*.log" # 查找指定777权限 find ./ -perm 777 # 查找空目录 find ./ -type d -empty # 查找空文件 find ./ -type f -empty # 查找用户为root的文件 find / -user root # 查找属组是root的文件 find / -group root # 查找大小在30M到100M的文件 find ./ -size +30M -size -100M -type f # 查找777权限,打印并改为700,结尾{} \;是必需的 find ./ -perm 777 -print -exec {} \; - locate:相对较快的查询,但需要提前用updatedb构建数据库,但只能查询名字,一般需要单独安装
其他常用指令
- 输出
- echo
# 普通字符串,可以不加双引号 echo 1 2 3 echo "1 2 3" # 双引号内可以对双引号进行转义 echo "\"haha\"" # 选项-e,开启使用其他转义 echo -e "new line \n" # 定向到文件(使用重定向时最好添加双引号以明确内容) echo "hello world" > test.log # 使用单引号时,字符串不做任何转义或变量引用 echo '$name\n' - printf
# 模仿库函数用法即可 printf format-string params ...
- echo
- 二进制查看hexdump
参数 含义 -n length 显示前length个字节 -C 单字节十六进制和ascii -c ascii -d 双字节十进制 -x 双字节十六进制 -s pos 偏移pos个字节开始输出 -e ‘“format” a/b “format1 “format2”’ 以指定输出格式打印具体参考 - 压缩tar:
参数 含义 -c 创建新的tar包 -x 解tar包 -t 列出tar包内容列表 -r 附加新的文件到tar -v -vv 打包、解包时显示文件名、显示文件全部属性 -k 保留旧文件不覆盖 -z -Z -j 调用gzip、compress、bzip2进行解压缩 -f file 从file解包,或打包成file -C path 解包到指定路径 - 示例:
# 将当前目录下所有文件打入package包 tar -czvf package.tar.gz ./* # 解压到/tmp tar -zxvf package.tar.gz -C /tmp/
- 示例:
- 用户管理useradd、groupadd、userdel、groupdel、usermod、groupmod、groups、id
- 这些命令主要对/etc/passwd、/etc/shadow、/etc/group三个文件进行维护,字段含义参考
# 创建用户liyicheng,并设定:登陆位置/tmp,主属组lyc # 附加属组ubuntu,home下不创建用户目录(-M),不创建同名用户组(-N) useradd -d /tmp/ -g lyc -G ubuntu -M -N liyicheng # 修改用户liyicheng:主属组为ubuntu,增加(-a)附加属组mysql # 改名为liyicheng2,改登录shell为zsh usermod liyicheng -g ubuntu -G mysql -a -l liyicheng2 -s /usr/bin/zsh # 删除用户在passwd、group、shadow、gshadow中的内容,并删除其主目录下文件 userdel -r liyicheng # 查看属组 groups liyicheng # 查看uid、gid等 id liyicheng # 添加普通用户组(添加-r则为系统用户组) groupadd li # 删除用户组(此时要求没有以li为主用户组的用户) groupdel li # 修改用户组li的gid为2333,名字为newli # groupmod 改组名和gid都容易会引起混乱,慎用 groupmod -g 2333 -n newli li - 权限管理chmod、chown
# 递归修改当前路径以下的文件、符号链接的用户为liyicheng,属组为li # 注:-L 不修改所有的符号链接(软链接),-H不修改目录的符号链接 chown -R liyicheng:li ./* # -c打印修改、-f屏蔽错误信息、-v为verbose、-R递归处理 # ugoa分别是用户、同组、其他、所有人 # rwx读写运行,Xst # 注:chmod永远不会修改符号链接的权限 chmod [-cfvR] [ugoa...][[+-=][rwxXst]...][,...] file - 统计
- wc:从文件&标准输入,默认分别统计并打印行数(-l)、单词数(-w),byte数(-c)
- 系统状态
- top、htop:查看系统综合信息和各进程
- free:查看内存信息
- df:查看磁盘使用情况
- du:查看文件的大小(默认只显示目录的占用大小)
参数 含义 -a 显示所有文件(含目录) -b 显示文件实际大小,单位byte -c 统计大小之和 -d n 只显示到第n层(n层以下只统计,不详细列出) –inodes 显示inode信息 -s 只列出整体结果 -X file 去除指定文件不计入统计 –exclude=pattern 去除匹配不计入统计(使用通配符?和*,非正则表达式)
- 进程管理ps、kill
- ps常用参数
参数 含义 -e 查看系统全部进程 -a 查看系统全部进程(session leader和未关联终端的进程除外) -d 查看系统全部进程(session leader除外) -f 展示进程全部信息 -j 以任务形式展示 -l 小写L,长展示格式 -H 以进程树格式展示 -pid 查看给定pid的进程 -C cmdlist 查询运行指定程序的进程,cmdlist形如"zsh ps” –sort=spec 以spec指定的列排序,正负号代表升降序(如uid,-ppid,+pid) -u userlist 查看指定用户的进程
- ps常用参数
- 文件查看cat、more、less、tail、head、sort
- sort是按行排序
# 常用参数,-r降序,-n数字对比,-k选择排序的参考列,-t选择行内的分隔符 sort -r -n -k 2 -t ":" # 支持多列组合,先按第一列降序,再按第二列 sort -k1nr -k2n - cat、more、less、tail、head都是查看用的,这里略去基本用法,展示一些额外实用的用法
# 合并文件 cat 1.txt 2.txt > 1and2.txt # 显示百分比、当前页行数范围、总行数,按顺序查看多个文件 # :n 下一个文件,:p 上一个文件 less -N -M *.log # 头部10行 head -n 10 test.log # 头部10个字节 head -c 10 test.log - sort是按行排序
- 链接ln
# 和cp、mv等类似,都是源文件在前 ln [options] source linkfile # 创建软链接(默认硬链接) ln -s boot.log boot-link.log - 网络工具集合
- 嗅探nmap
# 嗅探指定端口 nmap ip -p port # 嗅探全部端口 nmap ip - ssh详见ssh章节
- 网络传输scp(基于ssh的cp)
参数 含义 -1 -2 强制使用ssh1或ssh2 -4 -6 强制使用ipv4或ipv6 -C 大写 允许压缩Compress -p 保留源文件的属性(时间、权限) -r 递归复制 -v 经典verbose -c 小写 数据加密cipher -F ssh_config 使用指定的ssh配置 -P port 特定端口,也可以直接ip:port -l limit 小写的L 指定带宽限制Kb/s - 网络状态netstat
netstat无法看见全部端口,或者一些进程的pid的原因:进程不属于当前用户(可以通过sudo查看)
- 嗅探nmap
- 终端复用tmux
- 基本用法
# 创建名为test的tmux会话 tmux new -s test # 进入名为test的tmux会话 tmux attach -t test # 列出当前的所有tmux会话 tmux ls # 或者 tmux list-session # 进入第一个会话(如果你只有一个的话这样更快) tmux a # 杀死名为test的会话 tmux kill-session -t test # 杀死未处于使用状态(未attach)的所有会话 tmux kill-session # 重命名0号会话为zero tmux rename-session -t 0 zero # 加载tmux配置 tmux source-file xxx.tmux.conf - 命令模式:(在tmux内,并使用ctrl+b和冒号:)
# 修改tmux默认shell set-option -g default-shell /bin/zsh # 设置允许使用鼠标交互 set -g mouse on - 鼠标模式:(在tmux内,使用ctrl+b,之后使用PageUp/PageDown,就可以在控制台历史中翻找)
- tmux内:ctrl+b是所有快捷键的前置键,下面略去
会话内快捷键 含义 s 列出所有会话(可以借机跳转) $ 重命名当前会话 % “ 垂直、水平分割窗格 ; o 跳到上个、下个窗格 { } 和上个、下个窗格调换位置 x 关闭当前窗格 ! 将当前窗格提升为一个独立的窗口 z 当前窗格全屏 q 显示窗格编号(可以借机跳转) c 创建新窗口 p n 跳到上个、下个窗口 数字 跳到指定编号的窗口 , 窗口重命名 - 不同版本的tmux在配置上会有一些区分,注意使用
- 可以使用两个扩展:Tmux Resurrect(会话手动保存和恢复)、Tmux Continuum(会话定时保存和自动恢复)
- 基本用法
Shell编程
Shell编程的掌握一定要做大量的联系,参考牛客SHELL篇
- 基本概念
- 什么是shell:shell是用户使用操作系统的主要方式。同时包含交互式命令行和脚本两种使用方式。目前linux环境下常用的有:sh(Bourne shell)、bash(bourne again shell)、csh、ksh、zsh。bash是最常见的shell环境,大多数情况下sh和bash等价。
脚本文件内部首行,可以使用#!/bin/xxsh来指定执行使用的shell
- 什么时候用shell:想编写运行在类linux系统上的辅助程序,而且最好别太复杂。实际上如果对perl、python非常熟悉,可以使用这些相对高级的语言代替。
- 生命周期:用户登陆后会运行在自己的用户shell中,每一次运行一个shell脚本程序,系统将创建一个子shell来执行。子shell单向继承父shell的环境变量(普通变量不继承)。环境变量由export进行导出。
只有以source、或者是
.执行的脚本,才会在当前shell内进行。例如source my.sh,或者. my.sh。- IO
- 标准输入输出:键盘和显示器(当前终端)
- 重定向:
# > 重定向输出(覆盖) echo "233" > log # >> 重定向输出(追加) echo "666" >> log # < 重定向输入(本来等待键盘输入的,去读文件) read a < log; echo $a # 0标准输入、1标准输出,2标准错误文件 # 输出错误日志 command 2>log # 合并1、2输出到日志,&1意为取标准输出 command > log 2>&1 # 2>&1 不能有空格 - 管道:通过符号 | 将前一个命令结果传送给下一个命令
- 前后台
- 常用环境变量:PATH、CLASSPATH、JAVA_HOME等等
- /etc/profile:对所有用户永久生效
- ~/.bashrc:对单一用户永久生效
- 核心语法
- 变量定义:英文、数字、下划线
# 基本写法,等号左右不允许有空格 # 实际上,空格会导致表达式被解析成命令+参数 name="first name" # 赋值永远不要加$ name="second name" # 语句赋值 for name in `ls *.log` # 调用 echo $name # 使用花括号标识边界 echo "file ${name}Log" # 删除 unset name # 标记为只读变量(不可删除) readonly name - 数据类型
- 字符串:
# 双引号:内部可用\\转义,可以使用$引用变量 my_str="233\t${name}" # 单引号:内部所有的字符都以原样输出 my_str='233\t${name}' # 两种引号都是前后直接拼接 my_str="233"${name}$"hello" # 获取长度${#},对字符串有效 echo ${#my_str} # 子字符串提取方法,first:len my_str=${my_str:1:4} # 查找字符(注意是查找字符),例如3和h,返回第一个出现的字符 # 返回值从1开始(代表下标0),如果未找到,返回0 expr index ${my_str} 3h - 数组:
# 用括号定义,以空格分隔,数组下标从0开始 my_array=(1 2 3) # 也可以单独定义,允许空洞 my_array[5]=6 # 类型多变 my_array2=(1 "23" ${my_array[@]}) # 引用 echo ${my_array[3]} # 获取全部元素 echo ${my_array[@]} # 获取总长度 echo ${#my_array[@]} # 获取某个元素的长度 echo ${#my_array[2]} - 字典
# 使用前需要声明 declare -A my_dict my_dict=([key1]=23 [1.1]='236') # 打印全部key echo ${!my_dict[@]} # 打印全部value echo ${my_dict[@]}
- 字符串:
- 参数:
- 内置参数:
参数写法 含义 $# 传递到脚本内的参数个数 $* 以一个单字符串显示所有向脚本传递的参数 $$ 脚本运行的当前进程ID号 $! 后台运行的最后一个进程号 $@ 逐个分别输出所有参数 $- 显示shell的当前选项(每个字符都是shell选项) $? 前一个任务的返回值 !$ 将前一个命令的参数传递给当前命令做参数(实用)
- 内置参数:
- 运算符:
- 算术运算:原生bash并不支持(注意只是算术运算不支持),需要通过expr、let或其他指令实现。此时表达式和运算符之间必须有空格。
# + - * / % # 由于*有通配符的含义,必须进行转义 expr $a + $b \* $c / $d % $e -$f # 赋值 val=`expr $a + $b` - 关系运算符:==和!=支持字符串,其他运算符只支持数字,或者内容是数字的字符串
# 必须用[]括起来,而且内部必须有空格 # ps:[]内叫做条件表达式 if [ $a == $b ] then echo "a==b" fi # 此外还有!= -eq -ne -gt -lt -ge -le if [ $a -ge $b] then echo "a>=b" fi - 逻辑运算符:&&和||,一样左右需要有空格
- 字符串运算符
运算符 含义 = != 检测字符串是否相等/不等(在条件表达式内=和==等价) -z “$a” 字符串a长度为0返回true -n “$a” 字符串a长度不为0返回true $a 字符串a内容不为空返回true,外侧不要加双引号 - 文件测试:操作文件是shell编程的主要用途
运算符 含义 -b/-c/-d/-p file 是否为块设备、字符设备、文件夹、命名管道 -f file 是否为普通文件 -g/-u/-k file 是否设置了SGID、SUID、Stiky位(详见文件系统章节) -r/-w/-x file 是否可读、写、运行 -s file 是否不为空 -e file 是否存在 实际上文件测试语义都包含了是否存在,但为了便于记忆和理解,还是建议写上-e
- 算术运算:原生bash并不支持(注意只是算术运算不支持),需要通过expr、let或其他指令实现。此时表达式和运算符之间必须有空格。
- 流程控制
# if if condition1 then command1 elif condition2 then command2 else then command3 fi # for和零散变量 for var in item1 item2 item3 do commands done # for和数字列表(速度很快) for var in {1..500..2} do commands done # for和数组 for var in $my_array do commands done # for和命令,例如ls for var in $(ls) do commands done # while while condition do command done # 都可以写到一行 if xxx; then xxx; fi ; for xxx; do xxxx; done # case,匹配成功后则结束,不进行后续的模式匹配 case $val in pattern-1) commands ;; # 必须 pattern-2) commands ;; *) commands ;; esac # break 和 continue与其他语言大不相同 break n # 跳出n层循环 break # 跳出所有循环 continue n # 跳出n层循环 continue # 跳出当前循环 - 函数
# 定义 funcName () { echo $* echo $0 echo $1 # ... echo ${10} # 获取第十个,必须加括号 # 不写return则默认返回最后一个语句的返回值 } # 调用 funcName 1 2 3 4 5 - 调用外部脚本
# other.sh内 echo "this is other" # test.sh 内 # . other.sh . other.sh # source other.sh 也行 source other.sh
- 变量定义:英文、数字、下划线
- 经典例子
- 输入输出
echo '输入你的名字 <ctrl+c退出>' while read name do echo 'welcome ' $name ' to the system' done - 希望在前台执行,但是希望命令闭嘴
# /dev/null 黑洞 ping www.baidu.com > /dev/null
- 输入输出
- Shell环境
- 交互式shell和非交互式shell:字面就能理解,等待键盘输入的是交互式,在后台默默运行的是非交互式
- 登录式shell和非登录式shell:需要用户输入用户名密码才能开始使用的是登录式shell,而类似任务自动化执行的都是非登录式shell(非登录不代表没有用户)
- 登录式shell一般会读取的配置和顺序:/etc/profile(内部按顺序加载/etc/bash.bashrc,/etc/profile.d/*.sh),~/.bashrc(内部会加载/etc/bashrc等)。如果使用了zsh,则相应换为~/.zshrc
- 非登录式shell一般会读取的配置和顺序:~/.bashrc,/etc/profile。
常见的登录式shell:ssh、从tty登录;非登录式shell:从图形界面的终端打开的命令行,自动执行的shell。
- 几种自启动脚本写法
- upstart风格(略)
- init风格(pid=1是init)
- init.d:经典的init风格的启动方式,较老的系统
- rcX.d:X是运行级别,其内脚本会按顺序分别执行
- rc.local:最后一个执行的脚本(end of each multiuser runlevel),可在其内撰写脚本,该脚本执行完毕之后就是登录了。
- sysV风格(最为广泛使用,仍然是init的一种,pid=1是init)
- /etc/rc.d/init.d
- systemd风格(pid=1是systemd了,注意仍然可能使用软链接/sbin/init->/lib/systemd/systemd)
- /etc/systemd/system:编写.service文件
- 为了兼容,仍然会以某种形式保留init风格的一些服务
- crontab:定时任务,其中也有启动时运行的方法,弊端是无法确定系统的启动情况(比如网络是否已经连接)。编写后需要启动定时服务。
建议同时学习关于linux启动部分,init和systemd。
- 实用建议
- 引用变量尽量用双引号包括
- 不同shell并不完全相同(zsh和bash的起始数组下标就不同,且zsh默认不支持通配符),编写时请注意尽量指定所用的shell
修改zshrc,添加
setopt nonomatch以支持命令行通配符
- 快捷用法
- 历史记录
- 参考:Shell编程快速入门、shell部分经验、linux命令大全、Linux系统下如何设置开机自动运行脚本?
实用Shell案例
- 统计一个文件中的词汇和频率,按次数降序打印
# 生成 words.txt
echo the the day is sunny > words.txt
echo day is is >> words.txt
# 用split函数,用空格分割每一行,存储到arr,并用sum做统计
# sort排序
awk '{split($0,arr," "); for(i in arr) sum[arr[i]]+=1} END{for(i in sum) print i " " sum[i]}' words.txt | sort -r -n -k 2
- 匹配满足电话号要求的行,力扣链接
# 注意sed的转义、不转义情况
sed -n '/^[0-9]\{3\}-[0-9]\{3\}-[0-9]\{4\}$\|^([0-9]\{3\}) [0-9]\{3\}-[0-9]\{4\}$/p' file.txt
awk '{
# NF等变量可以直接使用
for (i=1;i<=NF;i++){
if (NR==1){
# $i的方式,获取第i列内容
res[i]=$i
}
else{
# 字符串连接
res[i]=res[i]" "$i
}
}
}END{
# 打印各列
for(j=1;j<=NF;j++){
print res[j]
}
}' file.txt
- 其他
# 打印空行行号,用=即可
sed -n '/^$/=' nowcoder.txt
# 打印非空行行号和内容
sed -n '/^.\+$/{=;p}' nowcoder.txt
# 打印所有短于8个字母的单词,使用了内置函数length
awk '{ for(i=1;i<=NF;i++){ if(length($i)<8) {print $i}} }'
# 计算内存占用总和(第四列的和,第一行表头不计算)
awk 'BEGIN{i=0; result=0} {i++; if(i>1) {result+=$4 }} END{print result;}'
# 查看第二列是否有重复,并按数量、单词字典序先后排序
awk '{ sum[$2]+=1;} END{for(i in sum) { if(sum[i]!=1) {print sum[i]" "i;}} } ' nowcoder.txt | sort -k1 -k2
# 判断每一行中所有的指定范围内的字符
awk '
BEGIN{
j=0;
total=0;
}
{
j++;
for(i=1;i<=length($0);i++){
temp=substr($0,i,1)
if(temp>=1&&temp<=5){
line[j]+=1;
total+=1;
}
}
}
END{
for(i=1;i<=NR;++i){
if(line[i])
print "line"i" number: "line[i]
else
print "line"i" number: 0"
}
print "sum is "total;
}' nowcoder.txt
# 更优雅的写法是用FS,设置将所有字符切割开
awk 'BEGIN{FS=""} {for(i=1;i<=NF;i++) { } ' nowcoder.txt
# 去掉所有包含this的句子
# awk的话,利用不匹配的正则,即!~
awk '$0 !~ "this"'
# 如果有更多要求,依然可以在""内添加正则
awk '$0 !~ "this|that"'
# sed则是利用不操作,!
sed -n "/this/!p"
# 求平均值,保留小数位数,由于shell不具备浮点运算能力(expr也不具备),awk几乎是唯一选择
awk '
BEGIN
{
N=0;i=0;
}
{
if(N==0){
N=$0;
}
else{
i+=$0;
}
}
END{
printf("%.3f", i/N);
}'
# 对一系列输入域名进行统计
# http://www.nowcoder.com/1/2/3
# 注意分割内容即使为空,也要占据$2
awk '
BEGIN{
FS="/";
}
{
sum[$3]+=1;
}
END {
for(i in sum){
print sum[i]" "i;
}
}
' | sort -k1nr
# 打印有且仅有一个数字的行
awk '$0 ~ "^[^0-9]*[0-9]{1}[^0-9]*$"'
# 统计日志中某一天的ip访问记录
awk '
{
if($4 ~ "23/Apr/2020")
sum[$1]+=1;
}
END {
for(i in sum){
print sum[i] " " i
}
}
' | sort -k1nr
其他指令收集
- 查看系统发行版:
# Red Hat系 & Ubuntu系
cat /etc/os-release
# Ubuntu系
cat /etc/issue
- 拷贝、转换文件dd:
# 从输入拷贝到输出
dd if=input.txt of=output.txt
# 拷贝512字节的0
dd if=/dev/zero of=zero.bin count=1
# 交换每两个相邻字节
dd if=input.txt of=output.txt conv=swab
- 查看cpu信息
lscpu
cat /proc/cpuinfo
- 查看所有环境变量:env
- 查看系统开机时间信息:uptime
- 系统级状态监控工具:sysstat
- iostat:cpu使用率,以及块设备、分区io效率
- mpstat:报告cpu相关数据
- pidstat:以进程为单位报告系统资源数据,I/O、cpu、内存等
- sar:收集、报告、存储系统活动信息
- sadc:sar的后端,收集器
- sa1:收集、存储二进制数据到系统日常数据文件,是sadc的前端,常用于定时调用
- sa2:收集统计报告,是sar的前端,常用于定时调用
- sadf:对sar采集的数据进行格式化,支持CSV、XML、Json,也可以继续接入图形化程序
- nfsiostat:NFS(Network File System)的I/O统计信息
- cifsiostat:CIFS(Common Internet File System)的I/O统计信息
- JVM性能调优工具:详解
- jps:查看java虚拟机进程,可以理解为java的ps命令
- jinfo:查看某个当前执行中的java虚拟机环境的参数,可以读取core文件了解当时的jvm配置
- 虚拟机的可配置参数可以通过以下指令查看
java -XX:+PrintFlagsFinal -version | grep managable
- 虚拟机的可配置参数可以通过以下指令查看
- jstack:观察所有线程的运行情况和状态,可以读取core文件复原内存信息、可以attach到java程序查看内存信息,查看的内存信息以栈区为主
- jstat:内存监视工具,查看JVM内各种内存使用
- jmap:查看物理内存的占用情况
- jconsole:一个java GUI监视工具,甚至支持X远程图形
- telnet:查询对指定端口
- nc:netcat,一个非常全面的网络指令,可以用于端口扫描、文件传输、创建IM会话
- last:查看最近的登录信息
- 对一些支持多版本并存的依赖项,进行版本管理
- update-alternatives
# 切换java版本 sudo update-alternatives --config java sudo update-alternatives --config javac
- update-alternatives
- 防火墙:firewall-cmd
# 查看所有开放端口 firewall-cmd --zone=public --list-ports # 添加80端口(permanent为永久,否则重启后失效) firewall-cmd --zone=public --add-port=80/tcp --permanent # 更新防火墙规则 firewall-cmd --reload # 添加端口转发 firewall-cmd --zone=public --add-forward-port=port=6603:proto=tcp:toport=3306 # 查看全部规则 firewall-cmd --list-all - 日志流转:logrotate
logrotate /path/to/your/log.config其中config文件内容规则形如
/var/log/yourApp/app.log { weekly create minsize 1M missingok rotate 4 }
一些建议
- 对于rm,可以替换为mv到临时文件夹,并定期清理,尽量避免使用rm,尤其禁止使用rm -rf