
C/C++:编译篇
目录
本文讲解编译构建过程中的一些进阶内容。以Linux GNU/GCC为主,也会包含部分其他编译器内容。
编译器版本
- MSVC:微软的C++版本。
- GNU/GCC:GNU系列的版本,在Linux系列操作系统中广泛使用
- gcc和g++都是compiler driver,分别负责调用真正的编译器cc1和cc1plus、汇编器as、链接器ld。
- gcc曾经是单指c语言编译器,但现在,它指的是GNU Compiler Collection,一系列编译器。
- Clang:C系语言的LLVM前端。
- LLVM:开源编译器后端。官方网站。
基本原理
预编译
- 输入:.c/cpp/cxx/hpp,输出一般写作.i/.ii。
- 处理内容:
- 删除注释
- #include:包含头文件,有<>和""两种,前者顺序为先搜索编译器选项-I目录、后搜索默认的标准库目录,后者在这两个前面再优先搜索当前文件所在目录。预编译会将头文件在源文件中展开。
- #define:宏定义
- #if/ifdef/ifndef/elif/else/endif:条件编译
- 添加行号和文件名标识
- 保留#pragma等编译器需要的指令
编译
- 输入:编译单元,即一个可以被编译的文件,如.c、.cpp、.hpp。.h文件不算。实际上进入编译阶段的,已经是由预处理器处理过的源文件了。现阶段预编译和编译一般已经合并为一个步骤。输出一般写作.s。
- 处理内容:词法分析、语法分析、语义分析、中间语言生成、优化、生成汇编代码
汇编
- 输入:汇编文件。输出目标文件。
- 处理内容:就是把汇编文件,转换成当前平台的机器码。输入的汇编文件实际上仍然是文本文件,但目标文件就是二进制文件了。
目标文件
- 编译后的文件类型:PC平台上的可执行文件大致分为Windows的PE(Portable Executable),和Linux的ELF(Executable Linkable Format)。目标文件(.obj/.o)只是尚未进行链接的文件,但内容上和可执行文件是高度类似的。
- ELF标准下的文件划分
文件类型 含义 例子 可重定位文件 包含代码和数据,只在编译期链接 目标文件.o、静态链接库.a 可执行文件 可以直接执行 bash 共享目标文件 包含代码和数据,编译期、运行期都可以进行链接 动态链接库.so 核心转储文件 保存的进程内存数据 core dump PE和ELF都是基于Unix System V Release 3提出的COFF格式发展出来的。
- 核心概念:段(Segment)
重要的段的名称 含义 .text 代码段 .rodata 只读数据(如字符串常量、条件语句的跳转表) .data 已初始化的全局变量和静态C变量 .bss 未初始化的全局变量和静态C变量 .symtab 符号表,存放程序中定义和引用的函数及全局变量 .interp 动态链接器路径 .rel.text 重定位条目,存储.text节中需要重定位的代码位置,即调用了外部函数和全局变量的位置 .rel.data 重定位条目,存储.data节中需要重定位的变量的信息 .debug 一个调试符号表,其条目存储了调试所需的类型信息,源代码等 .line 源代码和.text之间的映射关系 .strtab 字符串表,包括symtab、debug节中的符号表中符号的名称,以及各节的节名 并不是每个ELF文件都拥有全部的段,不使用-g时则没有debug/line段,可执行文件中一般则不包含重定位信息
链接
```bash
ld -o hello [依赖库] [各选项] hello.o
```
- 符号和符号表:
- 符号:对于可重定位文件,其符号表内存储着当前模块定义或者引用的符号的信息。主要有有三种符号
- 全局符号:非静态的C函数和全局变量,C++中的类函数(包括静态)、静态成员变量,这些符号能被其他模块引用
- 外部符号:由其他模块定义并被当前模块引用
- 局部符号:当前模块定义并使用的符号,如静态的C函数、静态全局变量、静态局部变量
- 符号表项具体内容:符号表是由汇编器构造的,通常来说具有以下结构
typedef struct { int name; // 在strtab表中的位置 char type:4, // 类型,函数还是数据 bind:4; // 局部还是全局 char reserved; // 保留 short section; // 所在节索引 long value; // 节中位置 long size; // 符号对象大小(字节) } Elf64_Symbol; - 符号重整:由于C++允许函数重载,因此很多方法具有相同的名字,为了链接器能够有效区分,编译器将会把所有的类、函数名、变量都进行重整,基本的方式是名称长度+原始名字+参数缩写(v,i,l),例如6Person7getNamev,注意重整名称并不包括返回类型,也正因如此,返回类型不能作为重载条件。
- 符号:对于可重定位文件,其符号表内存储着当前模块定义或者引用的符号的信息。主要有有三种符号
- 内部链接对象、外部链接对象
- 内部链接对象(Internal Linkage):例如使用static标记的变量,此时各个编译单元(即各个.o),各自使用该变量的不同副本。该副本对其他编译单元不可见。
- 外部链接对象(External Linkage):如果不同编译单元同时引用一个实例,即共享同一个地址的变量/函数,则是外部链接对象。
inline的一个用法:当头文件内出现全局函数时,避免出现重复定义,可使用inline标记为内部链接对象。同时也建议编译器将该函数直接嵌入在调用处。
- 静态链接:
- 地址和空间分配(Address and Storage Allocation)
- 符号解析(Symbol Resolution)
- 局部符号的解析是显而易见的,只需要保证定义且唯一即可。而且在这一步,编译器就不允许有同名符号。
- 外部符号的解析相对复杂。一般的符号将会被划分为强弱两种类型:注意下面的这些区分是针对链接器的,编译器对不同单元的符号,并不会进行区分。
- 强符号:函数和已初始化的全局变量
- 弱符号:未初始化的全局变量
- 一般的匹配规则:不允许多个同名强符号、强符号和强符号同名选强符号、多个弱符号同名则任选其一(优先选择占用空间最大的一个)
可以通过选项控制这些默认规则的行为,例如将这些编译、链接警告提升为错误。参考强符号和弱符号、C/C++多个链接库含有同名函数,编译会报错吗
- 解析过程:链接器维护一个可重定位目标文件集合E,一个未解析符号集合U,一个已定位符号集合D。对于输入处理的目标文件(.o)和存档文件(.a),将会按顺序添加、更新E、U、D三个集合
目标文件和存档文件的顺序可能非常重要,如果解析一个存档文件时,其符号均不在U集合内,则该存档文件将会被直接跳过,即使后面有需要,也会产生“无法解析的符号”的错误
- 重定位(Relocation)
- 重定位条目数据结构:
typedef struct { long offset; //需要重定位的引用在所在节中的偏移量 long type:32, //重定位类型 symbol:32; //需要重定位的符号在符号表中的索引 long addend; //重定位地址偏移量 } Elf64_Rela;编译阶段,每当汇编器发现一个无法确定位置的引用时,就会产生一个重定位条目。重定位条目和其引用所在的节是对应的。
- 重定位节和符号定义:链接器将来自所有输入文件的相同类型的节,合并到输出文件的该类型节中。例如各个文件的.data合并为一个大的.data,所有.rodata合并为一个.rodata。从这一步开始,函数、变量都具有自己真正的地址。
- 重定位节中的符号引用:链接器处理每一个重定位条目,修改其指向的代码节或数据节中各种符号的实际引用值,让他们指向正确的地址。典型的重定位地址计算包括相对地址、绝对地址两种。
可以理解代码就是一个字节流,其中指定位置的字节代表了符号引用的实际值,需要在链接期进行修改 强烈推荐阅读《深入理解计算机系统》480-482页
- 重定位条目数据结构:
- 动态链接:
- 静态链接的问题:将会增大程序的存储体积,也会增大程序运行时的内存占用。静态库升级必须重新编译。
- 共享库(shared library/object):一个目标文件,在运行或加载时可以被加载到任意的内存地址,并和一个内存中的程序链接起来。这个过程就是动态链接(dynamic linking)。
- linux下为so、windowsxia为dll
- 动态链接流程:
- 编译期指定,随程序加载:
- 创建动态链接库:编译阶段,对于库创建动态链接库
- 创建可执行目标文件:指定依赖的动态链接库,编译器将在可执行文件内记录这些动态链接库,包括重定位信息、符号表信息等
- 程序加载:加载器检查到存在.interp节,加载并执行动态链接器,动态链接器重定位所有依赖的动态链接库到内存,并将程序中的相关符号引用进行重定位。
- 运行期动态加载:
- 根据需求,调用系统提供的动态链接器接口,如Linux平台为函数dlopen
- 编译期指定,随程序加载:
- 位置无关代码(Position Independent Code,PIC):
- 问题:为了能让不同进程共享同一份内存中的动态库,需要做一些额外的工作。首先只有代码段和只读数据是可以共享的,每个使用到的进程仍然需要独立的读/写数据块。这就需要编译、加载期做一些事情。
- 编译选项:动态库本身是可以随意加载而不需要(也不应该)进行重定位的。这样就必须保证寻址仍能正确。
- 寻址方式:(仅描述基本原理)
- 动态库的目标模块代码段内部,可以很方便的通过相对地址进行寻址
- 引用全局数据:利用目标文件加载后相对距离不变的特性,构建全局偏移量表(Global Offset Table,GOT),编译时使用偏移量寻址,每一个引用了共享模块的进程都有自己的GOT,偏移值在共享模块加载时填充到GOT中。
- 引用外部函数:类似的方式来构造GOT,但同时还构造过程链接表(Procedure Linkage Table,PLT)。对外部函数的寻址处理使用延迟绑定来提高性能,GOT中外部函数的初始值是其PLT条目的第二个指令。每一个能被动态链接的外部库中的函数,都会有一个自己的PLT条目,第一次调用时该条目中的代码将会负责将自己在运行期的实际地址修改GOT中该函数的对应条目,非首次调用时PLT内会直接调用该GOT地址。
- GOT是数据段的一部分,PLT是代码段的一部分
PIC设计巧妙,建议阅读《深入理解计算机系统》491-492页
装载
- 概念
- 加载器:系统调用来启动加载器,加载器将可执行目标文件从磁盘复制到内存中,然后跳转到程序的第一指令或入口点。
- 进程管理:加载器的工作和进程管理相关,子进程是父进程的复制,加载器会把子进程的内存删除干净,并将可执行程序的内容拷贝到子进程的内存中。
- 虚拟内存系统:加载器加载可执行文件并非真正的加载,只有当CPU开始引用一个虚拟内存页时,才会真正从磁盘复制。
- 程序头部表:加载器需要使用的数据结构。ELF的连续的片段(chunk)将会被映射到连续的内存段。这种映射关系由程序头部表给出,可以通过objdump查看,主要就是标记每一个片段的大小,目标文件中的位置,映射到内存的地址,类型等
- 内存结构:以Linux x86-64为例。内核占用高地址$2^{64}-1$至$2^{48}$。之后是栈、堆、数据、代码、空白页。(空白页大小是0x400000,为了尽量保证空指针能触发空页异常,虽然通用的页是4KB,但仍设置为大页的4MB大小)
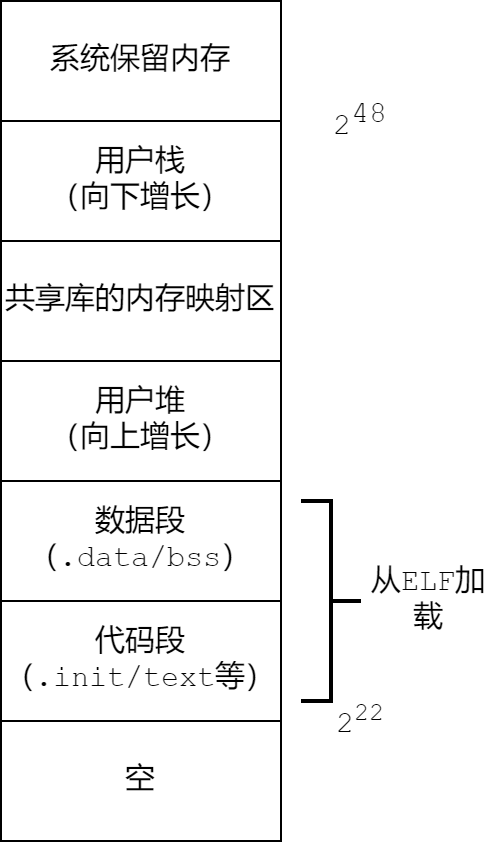
- 加载器:系统调用来启动加载器,加载器将可执行目标文件从磁盘复制到内存中,然后跳转到程序的第一指令或入口点。
库打桩
- 库打桩(library interpositioning):用来截获对共享库函数的调用
- 经典用法:
- 替换目标函数
- 包装目标函数
- 统计性能、追踪调用细节
- 打桩方式:
- 编译时:包装目标函数,并以#define等形式进行函数替换。用编译选项-I优先使用本地包装的头文件。
- 链接时:指定编译选项–wrap,提示链接器变更符号引用的解析方式。
- 运行时:修改LD_PRELOAD环境变量,指定共享库路径,优先加载这里的运行库。一般会由包装程序内部再以dlsym来动态加载原始目标函数。包装程序需要编译为动态链接库。
C和C++互操作
- C++中调用C代码:因为C++和C在链接层面上,会出现符号不一致的情况,因此如果C++想要调用C,必须进行一定的处理。才能使C语言生成的符号链接在C++的链接过程中可见。
- 在C语言的头文件中
// MSVC官方示例 // MyHeader.h // 必须限定只在C++内调用C的时候才通过条件编译 // C中没有extern "C"这种写法 #ifdef __cplusplus extern "C" { #endif #ifdef DLL_EXPORT // dllexport用于说明该函数,将要导出到dll为其他程序使用 // 可以通过编译器选项,控制函数默认不导出 __descspec(dllexport) void YourFunc(); #else // dllimport用于说明该函数,在链接使用的时候是由外部引入 // dllimport用于使用时 // 推荐添加,但实际上不添加也可能通过 __declspec(dllimport) void YourFunc(); #endif #ifdef __cplusplus } #endif - 在C++中使用C代码
// 真正重要的,这一步指示该编译单元是由C语言产生 extern "C" { #include "MyHeader.h" }
注意:C语言的代码单元仍然由C语言编译器完成编译。C++调用C时,通过
extern只是用来告知编译器和连接器,对于该部分代码,使用C风格的编译和链接方式(比如符号名)。 - 在C语言的头文件中
- C中调用C++代码:比较麻烦,因为C++中存在类和重载等特性,需要对这些内容进行一定的包装。
- C++中
// 完全正常编写的C++类型 // MyClass.h class MyClass { public: MyClass(); ~MyClass(); int DoSth(); } // MyClass.cpp #include<iostream> MyClass::MyClass() { std::cout<<"hello from MyClass constructor"<<std::endl; } MyClass:~MyClass() { std::cout<<"hello from MyClass deconstructor"<<std::endl; } int MyClass::DoSth() { // do sth. return 0; } // 为C调用准备的C++包装函数 // MyClassWrapper.h // 这个头文件最终会给C语言使用,因此必须用宏来控制属于C++的部分 #ifdef __cplusplus extern "C" { #endif void new_my_class(void **ptr); int do_sth_my_class(void **ptr); void release_my_class(void **ptr); #ifdef __cplusplus } #endif // 实现包装的源文件 // MyClassWrapper.cpp #include "MyClassWrapper.h" // 注意这个文件仍然是C++语言 #include <iostream> void new_my_class(void **ptr){ std::cout<<"before construct"<<std::endl; *ptr = new MyClass(); } int do_sth_my_class(void **ptr){ return ((MyClass*)*ptr)->DoSth(); } void release_my_class(void **ptr){ delete ((MyClass*)*ptr); } - C中
// main.c #include "MyClassWrapper.h" #include "stdio.h" int main(){ void *ptr; new_my_class(&ptr); do_sth_my_class(&ptr); release_my_class(&ptr); return 0; }
- C++中
常用指令
GCC & G++
- 概述:gcc和g++分别是GNU旗下用于c和c++的编译器
- 常用命令、选项示例:
# 用-o指定输出文件的名字 gcc main.c -o main # -E为只进行预编译 gcc -E hello.c -o hello.i # -S为只进行编译 gcc -S hello.i -o hello.s # -C(大写),生成文件保留注释,用于调试 gcc -C hello.c -o hello.o # 直接调用汇编器as as hello.s -o hello.o # 或者由gcc代劳 gcc -c hello.s -o hello.o # -c也支持直接从源码到目标文件 gcc -c hello.c -o hello.o # -pipe,使用管道避免产生临时文件 gcc -pipe -o hello.o hello.c # --warp指定链接时打桩 gcc --wrap malloc --warp free -o hello hello.c myMalloc.o # 等价于 gcc -Wl,--wrap,malloc -Wl,--wrap,free -o hello hello.c myMalloc.o - 其他实用编译选项:
选项 功能 -fno-common 禁止多重定义符号,提示错误 -Werror 将所有警告提升为错误 -w 不生成任何警告信息 -Wall 生成所有警告信息 -Wl 将在此选项后面的字符串传递给链接器,每个逗号替换为一个空格 -Wa 将在此选项后面的字符串传递给汇编器,规则同上 -fpic 指示编译器生成位置无关代码(动态链接库) –wrap xxx 将__warp_xxx的函数作为包装函数,在链接时绑定到xxx的符号引用上 -lxxx 指定链接所需要的库 -ldl 需要运行期实用动态链接器的程序,用此指示编译器链接dlfcn相关依赖库 -ansi 关闭gnu c中和ansi c不兼容的部分。用来专门支持ansi c的特性。 -include 添加指定的头文件 -Dxxx 为代码添加#define xxx -Dxxx=yyy 为代码添加#define xxx=yyy -Uxxx 为代码添加#undef xxx -undef 取消任何非标准宏的定义 -I路径 指定一个寻找头文件的路径 -L路径 指定库的寻找路径 -M、-MM、-MD 将所依赖的所有源代码包含到目标文件的一系列不同效果的选项 -O0/1/2/3 四个优化级别,默认1。0为不优化,3最高。 -static 禁止使用动态库,打包成全静态链接程序 -shared 尽可能使用动态库
GDB
- gdb是一个基于命令行的,交互式的debug工具。对于没有gui界面的情况,可以使用。但现在已经是2022年啦,如果有gui,还是建议用gui吧。
- 启用:
# 编译时需要至少打开-g选项 gcc -g main.c -o main # 使用gdb启动 gdb main # 可以使用gdb调试一个正在运行的服务 gdb 程序名 程序id - gdb常用指令:
命令 简写 功能 回车 重复执行上一条命令 list 行数/函数名 l 按顺序展示代码,每一次10行 start 开始执行,停留在main的第一条语句 run r 连续执行,直到遇到断点或结束 continue c 继续执行,直到断点或结束 next n 执行下一句 step s 进入正在执行的函数内部(step in) until 运行直到跳出循环体 finish 一直执行直到跳出当前函数(step out) info i info有大量选项,观察变量、堆栈、寄存器等 info 变量名 i 查看变量的值 set var 变量名=变量值 修改变量的值 print 表达式 打印一个表达式 display 变量名 程序每次停止都会显示该变量的值(监视) x/nbx 变量名 查看变量名开始之后的n个字节(指针、数组) backtrace bt 查看调用栈 frame n f 查看调用栈中的第n个栈帧 break 行数/函数名 [if 条件表达式] b 设置断点 watch 变量名/表达式 当程序访问指定变量的内存、表达式有变时触发断点 rwatch 变量名 变量被读时断点 awatch 变量名 变量被读写断点 ignore 断点号 n 忽略指定断点n次 info watchpoints/breakpoints 查看当前观察点、断点 condition 断点编号 断点条件 为断点添加条件 catch catch/throw 类型 C++专用,发现一个catch或throw时触发 commands 断点号 指令列表 end 设置在指定断点时执行的一系列指令 clear 行数/函数名/文件名 删除断点 delete breakpoints 断点编号 删除断点 enable/disable breakpoints 断点编号 启用/禁用断点 quit q 推出gdb - gdb命令行选项: | 选项 | 简写 | 功能 | | -tui | - | 用tui展示调试页面 |
- 条件断点的使用说明
# 创建普通断点 (gdb) break 10 # 注意gdb返回的断点编号为1 breakpoints 1 at 0x.... file ..., line 10 # 添加断点1条件,value不小于0 (gdb) condition 1 value>=0 # 类似的,观察断点 (gdb) watch value breakpoints 2 at .... (gdb) condition 2 value>=10 # 类似的,异常断点 (gdb) catch throw int break points 3 at ... (gdb) condition 3 value>100
常用项目级工具
autotools系列
如果所开发软件的主要平台是GNU Linux平台,那么使用autotools系列是一个很好的选择。它通过一系列组件,完成对Makefile的生成,并且由于已经有成熟稳定的GNU规范,通过相关命令和所要求的:install-sh、missing、depcomp、INSTALL、NEWS、 README、AUTHORS、ChangeLog、COPYING共9个文件。可以自动的完成在Linux系统平台上的组织、构建、安装、部署等工作。具体的顺序和作用如下:
- autoscan:在给定目录及其子目录树中检查源文件。扫描源代码以搜寻普通的可移植性问题,比如检查编译器,库,头文件等。生成configure.scan文件,该文件是configure.in(或configure.ac)的原型。
- aclocal:一个perl脚本程序。根据已经安装的宏,用户定义的宏和acinclude.m4文件(如果有的话)中的宏,将configure.in(或configure.ac)文件所需要的宏集中地定义到文件aclocal.m4中。
- autoheader:扫描configure.ac(或configure.in),根据其中的某些宏(比如cpp宏定义)产生宏定义的模板文件config.h.in
- autoconf:将configure.ac中的宏展开,生成configure脚本文件
- automake:选要自己写一个Makefile.am文件,然后automake根据configure.ac和Makefile.am中定义的结构,生成Makefile.in文件。automake需要上面提到的9种文件作为一个标准GPU程序的构建流程。
- configure:configure脚本会收集系统的信息,创建config.status(这个文件可用来重新创建configure脚本),使用Makefile.in来创建Makefile文件,使用config.h.in(如果有的话)来创建config.h文件,并生成一个日志文件config.log(记录一些创建时的调试信息等)
- make & make install & make dist & make uninstall
根据自己的需要,并不一定使用所有的工具,比如项目结构已经固定了,那么可以提供一个固定的aclocal.m4和configure.ac,后面的工作直接由autoconf开始完成。 参考GNU Autotools的研究(转)
CMakeLists
- 概述:CMake是一个跨平台的C/C++构建文件生成工具,也支持一些其他语言。但是最主要的功能还是给C/C++语言项目使用。其在Windows上一般生成Visual Studio工程,在Linux下一般生成Makefile。
- 用法:
- 编写CMakeLists.txt
- 编写对应的工程
- 惯用方式
mkdir build cd build cmake ../ make
- 以一个典型的CMakeLists.txt为例
# 指定所需要的cmake的最低版本 cmake_minimum_required(VERSION 3.10) # 设置C++编译环境需要支持支持标准11 SET(CMAKE_CXX_STANDARD 11) SET(CMAKE_CXX_STANDARD_REQUIRED True) # 设置项目名称 PROJECT(Tutorial VERSION 1.0) FIND_PACKAGE(Qt5 ) # 系统内省,判断是否能满足项目对平台或语言特性的需要 CHECK_CXX_SOURCE_COMPILES(" #include<cmath> int main(){ std::exp(1.0); return 0; } " HAVE_EXP) IF(HAVE_EXP) MESSAGE("EXP CHECK PASS") ENDIF() # 编译选项 OPTION(USE_MYDEP "使用自定义dep" ON) IF(USE_MYDEP) # 包含子文件夹dep的构建步骤 ADD_SUBDIRECTORY(dep) # 将头文件和依赖库添加进来 LIST(APPEND EXTRA_LIBS dep) LIST(APPEND EXTRA_INCLUDES "${PROJECT_SOURCE_DIR}/dep") ENDIF() # 根据需要引入到代码中 # CONFIGURE_FILE(...) # 添加生成的目标文件 ADD_EXECUTABLE(Tutorial tutorial.cpp) # 指定目标文件所需的链接库 target_link_libraries(Tutorial ${EXTRA_LIBS}) # 指定头文件的搜索路径 target_include_directories(Tutorial "${PROJECT_BINARY_DIR}" ${EXTRA_INCLUDES}) # 会被安装的文件 SET(export_targets Tutorial) SET(exports_includes Tutorial.h) # 安装类型,目的地 INSTALL(TARGETS ${export_targets} DESTINATION bin) INSTALL(FILES ${exports_includes} DESTINATION include) - 如果需要将宏从CMake引入到代码中,则需要配合专门指令
# CMake文件内 # .in文件需要一定的编写,.h则会由cmake自动生成 CONFIGURE_FILE(BuildConfig.h.in BuildConfig.h)// BuildConfig.h.in内 // 获取版本 #define VERSION_MAJOR @Tutorial_VERSION_MAJOR@ #define VERSION_MINOR @Tutorial_VERSION_MINOR@ // 获取选项宏 #cmakedefine USE_MYDEP - CMake的扩展模块提供了更加强大的使用能力,常用的如FetchContent(自动获取依赖库)
# 引入依赖库,需提供地址,下面是普通连接和GIT仓库两种形式 FetchContent_Declare( googletest GIT_REPOSITORY https://github.com/google/googletest.git GIT_TAG 703bd9caab50b139428cea1aaff9974ebee5742e # release-1.10.0 ) FetchContent_Declare( myCompanyIcons URL https://intranet.mycompany.com/assets/iconset_1.12.tar.gz URL_HASH MD5=5588a7b18261c20068beabfb4f530b87 ) # 该指令确保返回时,依赖项完成编译 FetchContent_MakeAvailable(googletest myCompanyIcons) - 一些基础指令指路:
名称 功能 PROJECT 设定项目名称、版本 ADD_EXECUTABLE 设定输出的目标可执行文件 ADD_LIBRARY 设定输出的目标库文件(可配置库类型) TARGET_COMPILE_FEATURES 指定目标文件的编译特性 FIND_PACKAGE 查找必要的依赖包 INSTALL 安装配置 IF 条件编译语句 MESSAGE 打印信息 SET 设置普通、用户可修改、不可修改、环境变量 ADD_CUSTOM_COMMAND 执行用户自定义脚本 EXPORT 将本项目导出(生成.cmake配置),给其他项目使用 - cmake常用指令
cmake -S . -B build # 当前目录为源文件目录(包含CMakeLists.txt),构建到build文件夹中 - cmake中的各种内置变量、命令行选项非常重要,可以多看多了解
平台相关
还是建议使用CMake等跨平台生成方案,在各平台上,根据需求也可以改用平台专属构建工具
- Mainfile
- Visual Studio
VSCode
VSCode中也可以进行一定程度的跨平台开发构建。其配置文件位于工程的.vscode文件夹内,主要文件有四个。都可以在VSCode中自动快捷生成一个模板配置。
- settings.json:保存项目的整体配置信息,例如,对于一个C++项目,典型的内容。在右下角选择
{ "C_Cpp.default.compilerPath": "/usr/bin/g++" } - c_cpp_properties.json:根据项目语言,会有不同的名称xx_properties。在这里配置相关语言的一些专用配置,比如标准、编译器路径等。
{ "configurations": [ { "name": "Linux", "compilerPath": "/usr/bin/g++", "cppStandard": "c++20", "intelliSenseMode": "linux-gcc-x64", "includePath": [ "${workspaceFolder}/**" ], "defines": [] } ], "version": 4 } - tasks.json:保存项目的一些执行任务,最常见的就是构建任务。通过终端(Terminal)→配置任务(Configure Tasks),会根据当前活跃文档自动尝试生成一个任务。其内容形如。
{ "version": "2.0.0", "tasks": [ { "type": "cppbuild", // 该任务的表示名称,对应launch中的preLaunchTask "label": "C/C++: g++ build active file", "command": "/usr/bin/g++", "args": [ "-fdiagnostics-color=always", "-g", "${file}", "-o", "${fileDirname}/main" ], "options": { "cwd": "${fileDirname}" }, "problemMatcher": [ "$gcc" ], "group": { "kind": "build", "isDefault": true }, "detail": "compiler: /usr/bin/g++" } ] } - launch.json:启动程序,对应Visual Studio中的运行、调试运行
{ "version": "0.2.0", "configurations": [ { "name": "C++ Launch", "type": "cppdbg", "preLaunchTask": "C/C++: g++ build active file", "request": "launch", "program": "${workspaceFolder}/main", "cwd": "${fileDirname}", "stopAtEntry": false, "targetArchitecture": "x64", "launchCompleteCommand": "exec-run", "linux": { "MIMode": "gdb", "miDebuggerPath": "/usr/bin/gdb" }, "osx": { "MIMode": "lldb" }, "windows": { "MIMode": "gdb", "miDebuggerPath": "C:\\MinGw\\bin\\gdb.exe" } } ] }
注意,相比之下,更推荐使用CMake。在编写了CMake之后,可以通过安装VSCode中的CMake插件,自动完成基于CMakeLists的构建和运行,实际上不需要再编写.vscode文件夹下的内容。
其他构建工具
测试工具
- Google Test
- 一个Google开源C++单元测试框架
- 参考:玩转GoogleTest
- GPerfTools
- FlameGraph
- GProf
交叉编译环境
C/C++很多时候可能需要自己准备交叉编译环境。这是一个相对复杂的构建需求。需要熟悉configure,以及gcc的一些基本原理参数。
首先我们必须有厂商提供的gcc、g++编译器。然后根据情况,可以自己试着(如果厂商没给),编译gdb和gdbserver。
而且由于一般来说交叉编译器会和既有的gcc冲突,推荐使用update-alternatives工具,进行gcc的版本管理
# 如果有需要,可以手动添加某个程序的候选版本,这里就是为/usr/bin/gcc这个软连接,创建了一个gcc-9的候选版本
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-9 100
# 当你有多个候选版本,就可以选择具体的环境
sudo update-alternatives --config gcc
需要先学一下gnu的autoconf工具族,至少要明白configure.ac/in、autoconf,以及configure之间的关系。必要的时候可能需要上手修改,甚至是修改Makefile。
如果过程中遇到了一些依赖库,找不到合适的安装包,也清大胆的自行编译吧!下面记录了一个在只有arm-linux-gcc编译套件的情况下,编译arm侧arm-linux-gdb和pc侧gdb的过程。
-
对于arm-linux-gdb:全程使用arm-linux-gcc进行交叉编译。
- 由于提供的arm-linux-gcc版本较低(4.4.3),尝试了多次不同版本的gdb,最终确定7.3版本的gdb是可用的
- 编译平台(pc)的ncurses-dev并不能用,我们需要为交叉编译环境,准备单独的ncurses。这里准备的是5.7版本。注意需要对ncurses进行交叉编译,而且需要准备动态库版本
./configure --build=i686-linux --host=arm-linux --target=arm-linux --with-shared - 在准备好ncurses后,需要修改gdb中的configure.ac,主要是指定到ncurses的库路径,例如
LDFLAGS="$LDFLAGS -L/your/path/to/your/ncurses/lib" LIBS="$LIBS -lncurses" # 此后会有AC_CHECK_LIB负责寻找库 # AC_CHECK_LIB(...) ./configure --build=i686-linux --host=arm-linux --target=arm-linux --prefix=./arm-gdb --enable-tui。enable-tui能够指定使用ncurses,而不是更老旧的termcap。实际上由于不需要编译sim,在libiberty、opcode等子模块完成编译后,就可以直接去gdb子目录下,只编译剩余的gdb的部分。并不需要将整个工程全部编译出来。在这一步也能得到gdb-server- 在gdb目录下,由于使用了ncurses依赖,我们需要修改config.in,将其中的ncurses宏改为如下的状态。并在工程的根目录下的include文件夹中,为其准备include所需的头文件
// #undef HAVE_NCURSES_NCURSES_H #define HAVE_NCURSES_NCURSES_H 1
-
对于pc侧的gdb:使用pc侧gcc(我用的版本是ubuntu17.04,gcc6.3)进行编译,一定不要偷懒直接在arm-linux-gdb工程下弄,新开一个工程(否则可能有之前没删干净的东西)
- 整体流程基本一致,但是需要注意ncurses也要生成pc侧版本(这一步系统内安装的ncurses其实是可用的了)。gdb的configure参数是比较特别的
--host=i686-linux --target=arm-linux - 但是值得注意的是,gcc6.3会报很多在arm-linux-gcc下不报的错误,对于这些情况,修改Makefile(Makefile.in),例如
# 对bfd -Wno-error=sizeof-pointer-memaccess -Wno-error=unused-value # 对opcode -Wno-error=shift-negative-value - 最后
make install
在这一步,由于我是在虚拟机内编译的gdb,并尝试远程链接一个arm板子上刚刚自己编译出来的gdb-server。虽然能够连接,但是并不好用,感觉还是有问题。在arm板子性能足够的情况下,还是直接在板子上使用arm-linux-gdb,直接调试。
怀疑可能是缺少了一些依赖。现在会报错remote packet g reply is too long。
- 整体流程基本一致,但是需要注意ncurses也要生成pc侧版本(这一步系统内安装的ncurses其实是可用的了)。gdb的configure参数是比较特别的
在这次编译的过程中,还尝试过gdb5.3和gdb6.0版本的代码。但是这两个版本的代码中,有很多问题,比如对ncurses的include路径准备的不好。甚至代码中存在很多的错误(转型的临时变量做了左值)等。在尝试修改之后,也能得到编译结果,但是最终在嵌入式平台和pc侧运行起来的时候。gdb会崩溃。总之在编译gdb的时候,不要企图改代码,如果有问题,换个版本试一下。
参考:
- gnu代码官方ftp仓库
- gdbserver: error: sys/reg.h: No such file or directory
- linux下gcc版本切换
- arm-linux-gdb & gdbserver 远程调试工具的搭建与使用
一些坑
- Linux/Ubuntu
- 使用cmake时,可能会出现错误:check for working C compiler: /usr/bin/cc – broken
# 尝试安装必要的包 sudo apt install build-essential # apt安装可能会失败,提示有无法满足的依赖 # 如上述失败,可以换用aptitude,更智能的包管理 sudo apt install aptitude sudo aptitude install build-essential # 接下来会提示一些可行的解决方案,升级、降级等谨慎选择
- 使用cmake时,可能会出现错误:check for working C compiler: /usr/bin/cc – broken
- CMake
- SET(CMAKE_INSTALL_PREFIX)无效:和SET本身有关,可以使用SET(CMAKE_INSTALL_PREFIX “/your/path” CACHE PATH “注释” FORCE)。方法来源
- 实际上应当尽量不使用FORCE,应该用链接中的方法。
- SET(CMAKE_INSTALL_PREFIX)无效:和SET本身有关,可以使用SET(CMAKE_INSTALL_PREFIX “/your/path” CACHE PATH “注释” FORCE)。方法来源
其他常用指令
- objdump
选项 含义 -h 查看简略的各段的头部信息 -x 查看各段较详细信息,符号表单独显示 -s 以十六进制打印 -d 输出反汇编代码 - readelf:看符号表更好用一些
选项 含义 -s 查看符号表 -e 查看节头信息 - ar:从目标文件(.o)创建静态库(.a),ar [options] archive_file object_files …
选项 含义 r 创建、替换已有.a或向其插入新内容 - strings:列出目标文件中所有可以打印的字符串
包括用户的常量字符串,以及各个节的名字,函数名、文件名等等
- nm:列出目标文件的符号表中的符号
- size:列出目标文件中节的名字和大小
- strip:删除目标文件中的非必要符号表信息,如debug等辅助信息
- ldd:列出所有该可执行文件运行所需要的共享库
- windows下:
- cl:msvc编译器
- link:msvc链接器
- dumpbin:msvc的COFF/PE文件查看器